
This guide from Logz.io for Docker monitoring explains how to build Docker containers and then explores how to use Filebeat to send logs to Logstash before storing them in Elasticsearch and analyzing them with Kibana.
The popular open source project Docker has completely changed service delivery by allowing DevOps engineers and developers to use software containers to house and deploy applications within single Linux instances automatically.
The ELK Stack is a collection of three open-source products: Elasticsearch, Logstash, and Kibana. Elasticsearch is a NoSQL database that is based on the Lucene search engine. Logstash is a log pipeline tool that accepts inputs from various sources, executes different transformations, and exports the data to various targets. Kibana is a visualization layer that works on top of Elasticsearch.
Filebeat is an application that quickly ships data directly to either Logstash or Elasticsearch. Filebeat also needs to be used because it helps to distribute loads from single servers by separating where logs are generated from where they are processed. Consequently, Filebeat helps to reduce CPU overhead by using prospectors to locate log files in specified paths, leveraging harvesters to read each log file, and sending new content to a spooler that combines and sends out the data to an output that you have configured.
This guide from Logz.io, a cloud-based log management platform that is built on top of the open-source ELK Stack, will explain how to build Docker containers and then explore how to use Filebeat to send logs to Logstash before storing them in Elasticsearch and analyzing them with Kibana.

A few things to note about ELK
Before we get started, it’s important to note two things about the ELK Stack today. First, while the ELK Stack leveraged the open source community to grow into the most popular centralized logging platform in the world, Elastic decided to close source Elasticsearch and Kibana in early 2021. To replace the ELK Stack as a de facto open source logging tool, AWS launched OpenSearch and OpenSearch Dashboards as a replacement.
Second, while getting started with ELK is relatively easy, it can be difficult to manage at scale as your cloud workloads and log data volumes grow – plus your logs will be siloed from your metric and trace data.
To get around this, Logz.io manages and enhances OpenSearch and OpenSearch Dashboards at any scale – providing a zero-maintenance logging experience with added features like alerting, anomaly detection, and RBAC.
If you’d rather not spend the time to install or manage ELK on your own, check out Logz.io Log Management.
Alas, this article is about setting up ELK for Docker, so let’s get started.
Creating a Dockerfile
This section will outline how to create a Dockerfile, assemble images for each ELK Stack application, configure the Dockerfile to ship logs to the ELK Stack, and then start the applications. If you are unsure about how to create a Dockerfile script, you can learn more here.
Docker containers are built from images that can range from basic operating system data to information from more elaborate applications. Each command that you write creates a new image that is layered on top of the previous (or base) image(s). You can then create new containers from your base images.
Let’s say that you need to create a base image (we’ll call it java_image) to pre-install a few required libraries for your ELK Stack. First, let’s make sure that you have all of the necessary tools, environments, and packages in place. For the sake of this article, you will use Ubuntu:16.10 with OpenJDK 7 and a user called esuser to avoid starting Elasticsearch as the root user.
The Dockerfile for java_image:
FROM ubuntu:16.10 MAINTAINER Author name RUN apt-get update RUN apt-get install -y python-software-properties software-properties-common RUN \ echo oracle-java8-installer shared/accepted-oracle-license-v1-1 select true | debconf-set-selections && \ add-apt-repository -y ppa:webupd8team/java && \ apt-get update && \ apt-get install -y oracle-java8-installer RUN useradd -d /home/esuser -m esuser WORKDIR /home/esuser ENV JAVA_HOME /usr/lib/jvm/java-8-oracle
By calling on docker build -t java_image, Docker will create an image with the custom tag, java_image (using -t as the custom tag for the image).
To ensure that your image has been created successfully, you type docker images into your terminal window and java_image will appear in the list that the Docker images command produces.
It will look something like this:
java_image latest 61b407e1a1f5 About a minute ago 503.4 MB
Assembling an Elasticsearch Image
After building the base image, you can move onto Elasticsearch and use java_image as the base for your Elasticsearch image. The rest of the command will download from the Elasticsearch website, unpack, configure the permissions for the Elasticsearch folder, and then start Elasticsearch.
Because of the nature of Docker containers, once they are closed, the data inside is no longer available and the new running Docker image will create a brand new container. You will need to create a specific configuration for each service (if it requires a configuration) and then pass the configuration onto your image using the ADD Dockerfile command. You do not want to go into each new running Docker image inside its container and manually configure the service.
Before you start to create the Dockerfile, you should create an elasticsearch.yml file. I usually do this in the same location as the Dockerfile for the relevant image:
cluster.name: docker-example node.name: docker-node-1 path.data: /home/esuser/data network.host:0.0.0.0
The Dockerfile for the Elasticsearch image (remember java_image is your base image) should look like this:
FROM java_image MAINTAINER Author name ENV DEBIAN_FRONTEND noninteractive RUN mkdir /data RUN \ wget https://download.elasticsearch.org/elasticsearch/release/org/elasticsearch/distribution/tar/elasticsearch/2.1.1/elasticsearch-2.1.1.tar.gz && \ tar xvzf elasticsearch-2.1.1.tar.gz && \ rm -f elasticsearch-2.1.1.tar.gz && \ chown -R esuser:esuser elasticsearch-2.1.1 # elasticsearch.yml and Dockerfile are on same location ADD elasticsearch.yml /home/esuser/elasticsearch-2.1.1/config/elasticsearch.yml ENTRYPOINT elasticsearch-2.1.1/bin/elasticsearch
Docker creates an Elasticsearch image by executing a similar command to the one for java_image:
docker build -t es_image .
Assembling a Logstash Image
Logstash image creation is similar to Elasticsearch image creation (as it is for all Docker image creations), but the steps in creating a Dockerfile vary. Here, I will show you how to configure a Docker container that uses NGINX installed on a Linux OS to track the NGINX and Linux logs and ship them out. This means that you will have to configure Logstash to receive these logs and then pass them onto Elasticsearch.
As mentioned above, we are using Filebeat first to isolate where logs are generated from, where they are processed and then to ship the data quickly. So, we need to use Filebeat to send logs from their points of origin (NGINX, Apache, MySQL, Redis, and so on) to Logstash for processing.
Use a Beats input plugin (this is a platform that lets you build customized data shippers for Elasticsearch) to configure Logstash, which will listen on port 5000:
input {
beats {
port => 5000
}
}
The output is easy to guess. You want Elasticsearch to store your logs, so the Logstash output configuration will be this:
output {
elasticsearch {
hosts => ["es:9200"]
}
}
Do not be confused by the es:9200 inside hosts and whether Logstash will know the IP address for es. The answers will be clear when you start to execute the Docker instances.
The complex part of this configuration is the filtering. You want to log NGINX and Linux logs. Filebeat will monitor access.log and error.log files for NGINX and syslog files for Linux logs. I will explain how Filebeat monitors these files below.
You can learn more in our guide to parsing NGINX logs with Logstash. For the purposes of this guide, you will use the same Logstash filter. (For Linux logs, however, use the default pattern for syslog logs in Logstash — SYSLOGLINE — for filtering.)
The final filter configuration is this:
filter {
if [type] == "nginx" and [input_type] == "access" {
grok {
match => [ "message" , "%{COMBINEDAPACHELOG}+%{GREEDYDATA:extra_fields}"]
overwrite => [ "message" ]
}
mutate {
convert => ["response", "integer"]
convert => ["bytes", "integer"]
convert => ["responsetime", "float"]
}
geoip {
source => "clientip"
target => "geoip"
add_tag => [ "nginx-geoip" ]
}
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
remove_field => [ "timestamp" ]
}
useragent {
source => "agent"
}
} else if [type] == "nginx" and [input_type] == "error" {
grok {
match => [ "message" , "(?%{YEAR}[./-]%{MONTHNUM}[./-]%{MONTHDAY}[- ]%{TIME}) \[%{LOGLEVEL:severity}\] %{POSINT:pid}#%{NUMBER}: %{GREEDYDATA:errormessage}(?:, client: (?%{IP}|%{HOSTNAME}))(?:, server: (%{IPORHOST:server})?)(?:, request: %{QS:request})?(?:, upstream: \"%{URI:upstream}\")?(?:, host: %{QS:host})?(?:, referrer: \"%{URI:referrer}\")?"]
overwrite => [ "message" ]
}
geoip {
source => "client"
target => "geoip"
add_tag => [ "nginx-geoip" ]
}
date {
match => [ "timestamp" , "YYYY/MM/dd HH:mm:ss" ]
remove_field => [ "timestamp" ]
}
} else if [type] == "linux" and [input_type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGLINE}" }
overwrite => [ "message" ]
}
}
}
For the moment, it does not matter how type and input_type fit in—it will become clear when you start to configure Filebeat.
Configure Logstash
The complete logstash.conf looks like this:
input {
beats {
port => 5000
}
}
filter {
if [type] == "nginx" and [input_type] == "access" {
grok {
match => [ "message" , "%{COMBINEDAPACHELOG}+%{GREEDYDATA:extra_fields}"]
overwrite => [ "message" ]
}
mutate {
convert => ["response", "integer"]
convert => ["bytes", "integer"]
convert => ["responsetime", "float"]
}
geoip {
source => "clientip"
target => "geoip"
add_tag => [ "nginx-geoip" ]
}
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
remove_field => [ "timestamp" ]
}
useragent {
source => "agent"
}
} else if [type] == "nginx" and [input_type] == "error" {
grok {
match => [ "message" , "(?%{YEAR}[./-]%{MONTHNUM}[./-]%{MONTHDAY}[- ]%{TIME}) \[%{LOGLEVEL:severity}\] %{POSINT:pid}#%{NUMBER}: %{GREEDYDATA:errormessage}(?:, client: (?%{IP}|%{HOSTNAME}))(?:, server: (%{IPORHOST:server})?)(?:, request: %{QS:request})?(?:, upstream: \"%{URI:upstream}\")?(?:, host: %{QS:host})?(?:, referrer: \"%{URI:referrer}\")?"]
overwrite => [ "message" ]
}
geoip {
source => "client"
target => "geoip"
add_tag => [ "nginx-geoip" ]
}
date {
match => [ "timestamp" , "YYYY/MM/dd HH:mm:ss" ]
remove_field => [ "timestamp" ]
}
} else if [type] == "linux" and [input_type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGLINE}" }
overwrite => [ "message" ]
}
}
}
output {
elasticsearch {
hosts => ["es:9200"]
}
}
The Dockerfile for the Logstash image is this:
FROM java_image MAINTAINER Author name ENV DEBIAN_FRONTEND noninteractive RUN \ wget https://download.elastic.co/logstash/logstash/logstash-2.1.1.tar.gz && \ tar xvzf logstash-2.1.1.tar.gz && \ rm -f logstash-2.1.1.tar.gz && \ chown -R esuser:esuser logstash-2.1.1 # logstash.conf and Dockerfile are on same location ADD logstash.conf /home/esuser CMD logstash-2.1.1/bin/logstash -f logstash.conf --verbose
Now, build the Logstash image with the same command that you had used for the previous image:
docker build -t logstash_image

Creating a Kibana Configuration File
To create a Kibana configuration file next to your Dockerfile, use kibana.yml. You can create configuration files next to a Dockerfile to help to create images, but in theory, you can store configuration files — or any type of file — inside a Dockerfile. Just make sure that the locations inside the Dockerfile are stated properly.
A complete kibana.yml configuration file is this:
server.port: 5601 server.host: "0.0.0.0" elasticsearch.url: "http://es:9200" A Dockerfile looks like this:
$ sudo apt-get update
FROM java_image MAINTAINER Author name ENV DEBIAN_FRONTEND noninteractive RUN \ wget https://download.elastic.co/kibana/kibana/kibana-4.3.1-linux-x64.tar.gz && \ tar xvzf kibana-4.3.1-linux-x64.tar.gz && \ rm -f kibana-4.3.1-linux-x64.tar.gz && \ chown -R esuser:esuser kibana-4.3.1-linux-x64 ADD kibana.yml kibana-4.3.1-linux-x64/config/kibana.yml ENTRYPOINT kibana-4.3.1-linux-x64/bin/kibana
Build the Kibana Docker image
Now, you can build the Kibana image with this:
docker build -t kibana_image
Booting the ELK Stack
Once the ELK Stack configuration is complete, you can start it. First, start with Elasticsearch:
docker run --user esuser --name es -d -v es_image
If, for example, you have to stop and restart the Elasticsearch Docker container due to an Elasticsearch failure, you will lose data. By default, Docker filesystems are temporary and will not persist data if a container is stopped and restarted. Luckily, Docker provides a way to share volumes between containers and host machines (or any volume that can be accessed from a host machine).
The command to keep data persistent is:
docker run --user esuser --name es -d -v /path/to/data/:/home/esuser/data es_image
The host path always comes first in the command and the: allows you to separate it from the container path. After executing the run command, Docker generates a Container ID that you can print on your terminal.
Next, start Logstash:
docker run -d --name logstash --link es:es logstash_image
Notice that there’s a new flag in the code: –link.
When you configured the Logstash output earlier, the property es:9200 was inside hosts (where Logstash is supposed to send logs). While we mentioned that we would provide you with an answer on how Docker would resolve this host, we did not touch on the Linux network configuration.
To answer that issue, the –link flag shows you that the container will resolve es hosts. You can learn more about container linking in Docker’s documentation.
The last piece in our stack is Kibana:
docker run --name kibana --link es:es -d -p 5601:5601 --link es:es kibana_image
This, too, comes with a new flag, -p, that allows you to expose container port 5601 to host machine port 5601.
After Kibana is started successfully, you can access it using: http://localhost:5601. However, your Elasticsearch is still empty, so we need to fill it.
The missing pieces to the puzzle are NGINX instances (in a Linux OS) that will generate NGINX logs together with Linux logs. Filebeat will then collect and ship the logs to Logstash.
Here’s how to create your Filebeat image. First, a Dockerfile for Filebeat looks like this:
FROM java_image MAINTAINER Author name ENV DEBIAN_FRONTEND noninteractive RUN \ wget https://download.elastic.co/beats/filebeat/filebeat-1.0.1-x86_64.tar.gz && \ tar zxvf filebeat-1.0.1-x86_64.tar.gz && \ rm -f filebeat-1.0.1-x86_64.tar.gz ADD filebeat.yml filebeat-1.0.1-x86_64/filebeat.yml
Whereas the filebeat.yml looks like this:
filebeat: prospectors: - paths: - /var/log/nginx/access.log input_type: access document_type: nginx - paths: - /var/log/nginx/error.log input_type: error document_type: nginx - paths: - /var/log/syslog input_type: syslog document_type: linux registry_file: /home/fb_registry.filebeat output: logstash: hosts: ["logstash:5000"] worker: 1
The answer to the question in the Logstash configuration section on the sources of the type and input_type properties is that Filebeat added the types that you added inside the configuration to each log. The registry_file flag is used to store the state of files that were recently read, and this is useful in situations where logs are persistent.
Use this command to build the Filebeat image:
docker build -t filebeat_image
Creating an NGINX Image
The last step is to create an NGINX image. However, you need to configure NGINX before you start:
daemon off;
worker_processes 1;
events { worker_connections 1024; }
http {
sendfile on;
server {
listen 80;
root /usr/share/nginx/html;
}
}
The most important part of this configuration is the first line that says not to spawn after starting NGINX (otherwise the container will stop).
The Dockerfile for NGINX is this:
FROM filebeat_image MAINTAINER Author name ENV DEBIAN_FRONTEND noninteractive WORKDIR /home/esuser RUN apt-get update RUN apt-get install -y wget RUN wget -q http://nginx.org/keys/nginx_signing.key -O- | apt-key add - RUN echo deb http://ppa.launchpad.net/nginx/stable/ubuntu wily main >> /etc/apt/sources.list RUN echo deb-src http://ppa.launchpad.net/nginx/stable/ubuntu wily main >> /etc/apt/sources.list RUN apt-get update RUN apt-get -y install nginx pwgen python-setuptools curl git unzip vim rsyslog RUN chown -R www-data:www-data /var/lib/nginx RUN rm -v /etc/nginx/nginx.conf ADD nginx.conf /etc/nginx/ WORKDIR /etc/nginx CMD /home/esuser/filebeat-1.0.1-x86_64/filebeat -c /home/esuser/filebeat-1.0.1-x86_64/filebeat.yml >/dev/null 2>&1 & service nginx start
And finally, the NGINX image:
docker build -t nginx_image
Now that the last piece of the puzzle is complete, it’s time to hook it up to the ELK Stack that you installed earlier:
docker run -d -p 8080:80 --link logstash:logstash nginx_image docker run -d -p 8081:80 --link logstash:logstash nginx_image
When you work with persistent logs, you need the -v flag. This is called logging via data volumes so that the modified versions of commands listed above are these:
docker run -d -p 8080:80 --link logstash:logstash -v /path/to/the/nginx/log:/var/log/nginx -v /path/to/syslog:/var/log/syslog nginx_image docker run -d -p 8081:80 --link logstash:logstash -v /path/to/the/nginx/log:/var/log/nginx -v /path/to/syslog:/var/log/syslog nginx_image
Now, what should you do with Filebeat? Do you need two instances, or will one suffice? The answer is straightforward. You can still work with one Filebeat instance because you can share different locations of volumes on your host machine, and this is enough to separate logs on NGINX instances.
Let’s say you start two instances with NGINX containers with these two commands, and one mapped with port 8080 and the other with port 8081. After some time, these two instances will generate enough logs, and we can see them in Kibana here: http://localhost:5601.
Using Docker Log Data
Here are a few of the ways that you can use the data.
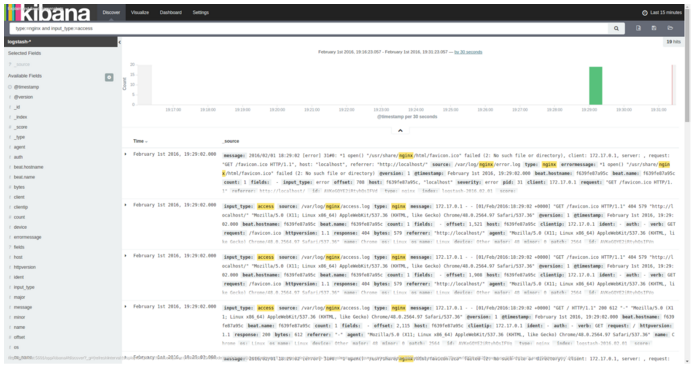
You can create a few charts on Kibana’s Visualize page and collect them in a customized dashboard.
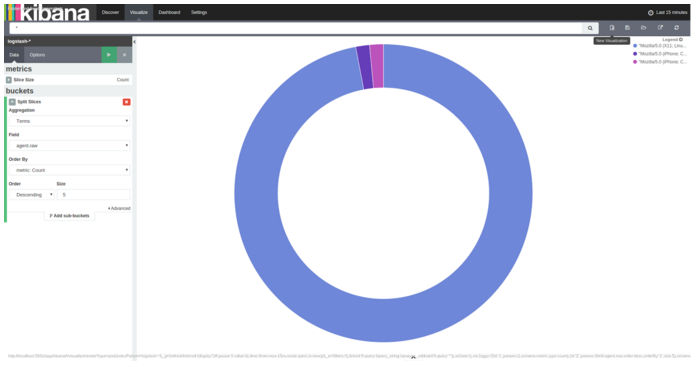
You can execute a query to track different browser agents that have visited published sites via Docker containers.
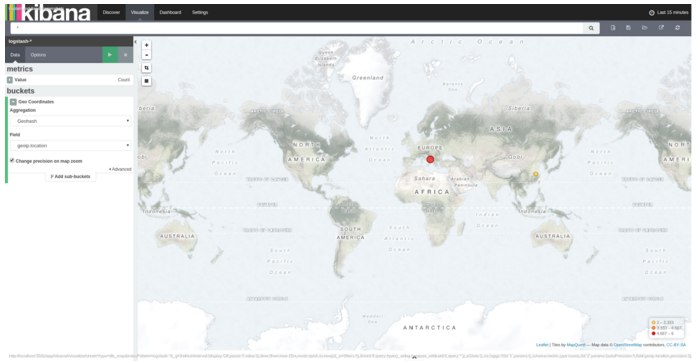
Kibana can create a map because Logstash searches for each IP address within the logs before sending them to Elasticsearch.
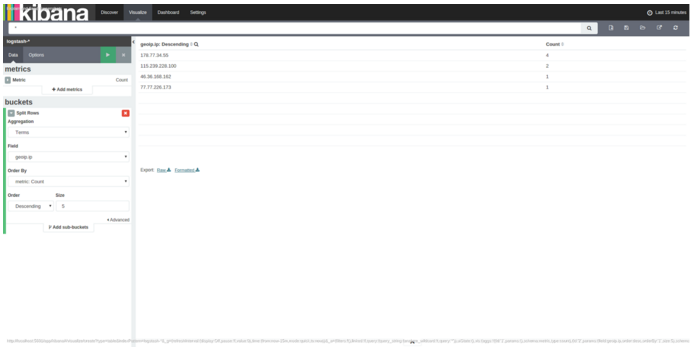
The data in Figure 3 can be displayed in table form, which can be used to check and filter for server abuse.
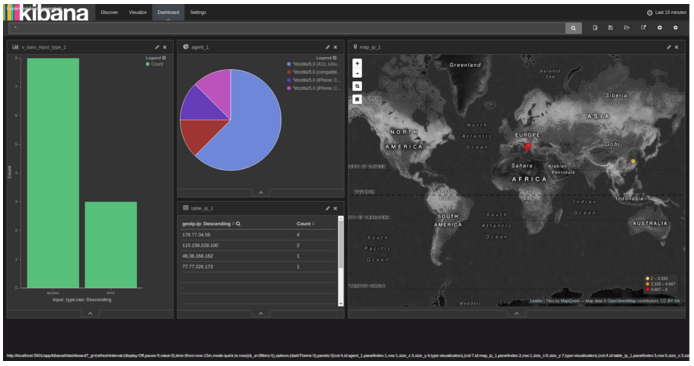
Figure 5 represents one possible way to customize your dashboard. This example was based on the charts in Figure 2 and Figure 4. (You can see our post on how to create custom Kibana visualizations.)
How to Log Docker Container Activity
Now that you’re more familiar with Docker, you can start logging container activity. You can start by examining the basics of Docker’s Remote API, which provides a lot of useful information about containers that can be used for processing. Then, you can monitor container activity (events) and analyze statistics to detect instances with short lifespans.
By default, the Docker daemon listens on unix://var/run/docker.sock. You must have root access to interact with the daemon. Docker leaves space to bind to other ports or hosts. Learn more.
Next, dump your Docker events into your ELK Stack by streaming data from the /events Docker endpoint. While there are probably several ways to do this, I will tell you two:
- Download the Docker-API library, which is written in Python and Ruby. Create a small script to stream data from the
/eventsDocker endpoint, which will redirect data to the file logging system that you created or send it directly to the exposed Logstash port. The second way is much easier than the first and involves binding. - Bind Docker to port 2375 by following the instructions here. (Ubuntu users have a different set of instructions.) Use the
wgetcommand to stream data in shared volumes that will be monitored and shipped by Logstash to Elasticsearch.
The starting command:
wget http://localhost:2375/events
The wget command will create a file named events in the working directory. However, if you want to give the file another name or location, the -O flag will do the job.
It’s important to know where wget streams data because you will have to share the file with your container.
This is a modified Logstash configuration:
input {
file {
path => "/home/esuser/events.log"
start_position => "beginning"
}
}
filter {
json {
source => "message"
}
}
output {
elasticsearch {
hosts => ["es:9200"]
}
}

Starting the ELK Stack
Now you have everything that you need to monitor Docker events, so it is time to get your ELK Stack up and running.
The command to start ELK is the same as above:
docker run --user esuser --name es -d -v /path/to/data/:/home/esuser/data es_image docker run --name kibana --link es:es -d -p 5601:5601 --link es:es kibana_image docker run -d --link es:es --name logstash -v /path/to/the/wget/events:/home/esuser/events.log logstash_image
After you enter a few commands to start and stop your containers and configure the shipped Docker event logs to Elasticsearch, Kibana will provide you with data. If you visit http://localhost:5601, you should see a similar screen to this one:
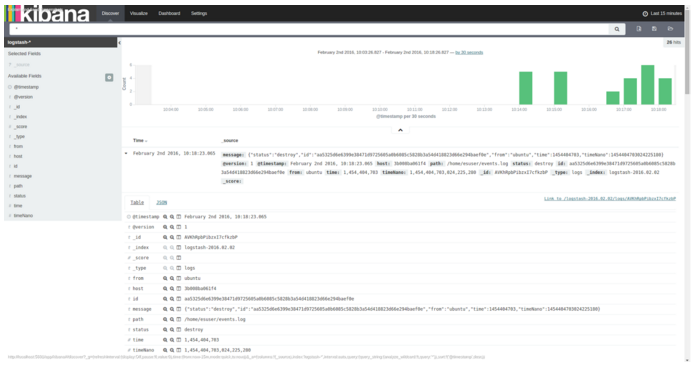
The main challenge here is to detect Docker instances with short lifespans. So, before we move to solve this problem and creating a query, we have to define what is considered “short” because it is a subjective term that means different things in different types of systems. Therefore, a predefined threshold needs to be defined first.
Now that you’ve equipped Elasticsearch with enough information to calculate these statistics, simply subtract the “die” timestamp for a particular container ID from the “start” of the event. The result represents the lifespan of your Docker instances.
This is a complex query that requires the introduction of a scripted metric aggregation. A scripted metric essentially allows you to define map and reduce jobs to calculate a metric, which in this case requires subtracting the “die” events from the “start” events in a particular container ID.
A query that calculates a container’s lifespan looks like this:
{
"size": 0,
"query": {
"filtered": {
"filter": {
"bool": {
"should": [
{
"term": {
"status.raw": "die"
}
},
{
"term": {
"status.raw": "start"
}
}
]
}
}
}
},
"aggs": {
"by_container_id": {
"terms": {
"field": "id.raw"
},
"aggs": {
"live_session": {
"scripted_metric": {
"map_script": "_agg['d']=doc",
"reduce_script": "start_time=0; die_time=0; for(a in _aggs) { if(a.d['status.raw'].value=='start') {start_time = a.d['time'].value}; if(a.d['status.raw'].value=='die') {die_time = a.d['time'].value}; }; diff = die_time - start_time; if(diff > 0) return diff"
}
}
}
}
}
}
This query can be applied to previously defined structures that Logstash previously shipped to Elasticsearch.
The result of the query looks like this:
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 5,
"max_score": 0,
"hits": []
},
"aggregations": {
"by_container_id": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "df43acbfe88480354bd48005b70afa2b34dec1b40a878a7d90adf2ed458af449",
"doc_count": 2,
"live_session": {
"value": 68
}
},
{
"key": "8e127e7d0ca9b665f9e7b20bedfc79624f8670c0ed2c6879941c6faf7329e502",
"doc_count": 1,
"live_session": {
"value": null
}
},
{
"key": "a2b789c58d5df54014acd2689bcef74f078732ea036f7a511804e42db7423a22",
"doc_count": 1,
"live_session": {
"value": null
}
},
{
"key": "e68596b37aace3300700d410432be349806e0a17df9b5a5057f38e476995b13b",
"doc_count": 1,
"live_session": {
"value": null
}
}
]
}
}
}
Notice how the containers with live_session.value NULL either have not died yet or could be missing part of the “start/die” event pair.
The query above calculates the lifespan (in seconds) for each container in Elasticsearch. The query can be modified to dump containers with a certain lifespan by simply changing the last condition in the reduce script. If you are interested in getting statistics for a particular timestamp period, the filter property can be modified to contain the timestamp range.
Ideas for Future Improvements
There are two approaches to logging. The one described above uses data volumes, which means that containers share a dedicated space on a host machine to generate logs. This is a pretty good approach because the logs are persistent and can be centralized, but moving containers to another host can be painful and potentially lead to data loss.
The second approach uses the Docker logging driver. There are several ways to accomplish this such as using the Fluentd logging driver in which Docker containers forward logs to Docker, which then uses the logging driver to ship them to Elasticsearch. Another approach uses syslog/rsyslog in which the shared data volumes for containers are removed from the equation, giving containers the flexibility to be moved around easily.



