Application Observability in 2024: An Ultimate Guide
February 8, 2024

In the fast-evolving landscape of IT and software development, ensuring the seamless functioning of applications is crucial. Traditional monitoring methods, while effective to some extent, fall short in providing a holistic understanding of these complex systems. This is where the concept of “application observability” comes into play.
Application observability is the fully modern and most strategic means of gaining a full understanding of how an application operates in real-time. It goes beyond traditional monitoring by incorporating logs, metrics, and traces to provide a deeper insight into the entire system.
The primary goal is to enable organizations to identify, troubleshoot, and resolve issues proactively – before they impact customer experience.
In this guide, we will provide you the ins and outs of application observability in 2024, how it impacts systems and processes across your organization, what you need to do to engage a successful practice, and how working with the right partners can get you to where you want to be.
Understanding Observability Beyond Logs, Metrics, and Traces
Observability involves the collection of data from various sources, including logs, metrics, and traces. This data is then consolidated, correlated and analyzed to gain insights into the application’s behavior — along with the state of supporting infrastructure. Advanced analytics are employed to correlate information and provide a conclusive view of the entire system.
Unlike traditional monitoring, which may provide isolated data points, observability aims to offer contextual insights. This means understanding not just what happened, but why it happened, providing a more current, detailed and nuanced view of system behavior.
Application observability ultimately enables organizations to move from a reactive to a proactive approach. By identifying potential issues before they impact users, organizations can maintain a higher level of service reliability.
The Importance and Benefits of Application Observability
One of the key benefits of application observability is the ability to address issues in real-time. Traditional monitoring might highlight a problem, but observability goes a step further by providing contextual information for a quicker and more accurate resolution.
For instance, using long-standing methods of Application Performance Monitoring (APM), analysis is based on the measurement of predetermined indicators and thresholds, versus dynamic conditions which may arise based on previously unexpected factors. The complexity of modern cloud applications and infrastructure running on ephemeral microservices and Kubernetes dictates this shift toward more flexible, real-time analysis.
This is a critical capability in a world where user experience is paramount. You need to have the clearest possible understanding of how users interact with production applications. With that as part of your arsenal, your developers can make data-driven improvements, resulting in a better overall experience, repeat customers, and the increased potential for more revenue.
Observability also helps in optimizing application performance and resource utilization. By analyzing metrics and traces, organizations can identify bottlenecks, inefficient code, or underutilized resources and make informed decisions to enhance efficiency.
Proactive issue resolution and optimized performance contribute to cost reduction. Application observability helps organizations identify areas where resources can be better utilized, leading to significant cost savings.
Observability further encourages collaboration among different teams within an organization. With a shared understanding of how applications and infrastructure actually function, development, operations, and security teams can work together more effectively.
How to Implement Application Observability
Implementing application observability is a multi-step process involving numerous stakeholders in your organization. It’s critical to get everyone on the same page before proceeding with the technical implementation, as we’ve attempted to lay out clearly in the following steps.
Define objectives. Clearly define the goals of implementing observability within your organization. What does your organization most want to achieve through application observability? What are the benchmarks you want to reach, and what will be your measures for success? Can you tie these efforts to business-driven SLOs?
Understand precisely what you want to achieve, such as reducing downtime, improving performance, or enhancing user experience.
Select tools and technologies. Choose the right observability tools based on your specific needs. Here are some factors to consider:
- Scalability: Ensure that the tools can handle the growing volume of data as your applications scale.
- Integration: Look for tools that seamlessly integrate with your existing infrastructure and development tools.
- Customization: Choose tools that allow for customization to meet the specific needs of your organization.
- Automation: Automation capabilities can streamline processes and enhance the efficiency of your observability practices.
You’ll also want to ask yourself some critical questions. What do you have in-house already, and what do you need to bring in from the outside? Are there existing tools that need to be optimized or repurposed, or re-applied for your success?
Instrumentation. Integrate observability into your applications through instrumentation. This involves adding code to collect relevant data without impacting performance. There are different ways to instrument your applications, and observability platforms such as Logz.io Open 360™ can help accelerate and simplify that process.
Data collection and storage. Set up the most efficient and straightforward processes for collecting, storing, and managing the vast amount of data generated by observability tools. Cloud-based solutions are often preferred for their scalability. Use of the OpenTelemetry (OTEL) framework has rapidly emerged as the de facto standard in today’s evolving observability landscape.
Data analysis and visualization. Implement analytics tools that can process and visualize the collected data effectively. Dashboards and reports should provide immediate, actionable insights for your teams. What kind of dashboards will best fit your use case? What do you want to track in the dashboards, and who will be responsible for maintaining them?
Training and Collaboration. Ensure that your teams are trained to leverage observability tools effectively. Foster collaboration between development, operations, and security teams to maximize the benefits of these tools, whether they are new or if they are being re-oriented to an application observability use case.
Application Performance Monitoring vs Application Observability
While performance monitoring and application observability share common goals, they differ in scope and approach.
Application Performance Monitoring (APM) typically focuses on specific metrics such as CPU usage, memory consumption, and response times. It provides a high-level view of system health but may lack the depth needed for troubleshooting complex issues. Significant time and effort is oriented toward instrumenting software code for this manner of analysis.
Application Observability, on the other hand, encompasses a broader range of data, including logs, metrics, and traces. It aims to provide a more comprehensive understanding of the application’s behavior, facilitating quicker problem resolution. Lesser focus on instrumentation is required, simplifying data collection and increasing efficiency, especially in light of OTEL use.
These two practices are not mutually exclusive; in fact, they complement each other. Organizations often benefit from combining performance monitoring with application observability to get a holistic view of their systems.
How Do You Make an Application Observable
Building an application doesn’t automatically mean your app will be observable. Here are the steps you need to take to get on the path to application observability:
Instrumentation: Integrate observability into your application code by instrumenting it with the necessary tools and libraries. This involves adding code to capture relevant data points, but not to the same extent as with APM.
Define Key Telemetry Types: Identify the key metrics, logs, and traces that are crucial for understanding your application’s behavior. This step ensures you collect meaningful data without overwhelming your system.
Centralized Logging and Monitoring: Set up a centralized logging and monitoring system to collect and store data efficiently. Cloud-based solutions can simplify this process and offer scalability.
Real-time Analysis: Implement real-time analysis tools that can process data as it’s generated. This allows for quick identification of issues and proactive problem resolution.
Alerting Mechanisms: Establish alerting mechanisms to notify teams when predefined thresholds are breached. This ensures timely responses to potential problems.
Continuous Improvement: Regularly review and refine your observability strategy. As your application evolves, so should your observability practices.
Challenges and Solutions in Application Observability
As with any technological journey, or effort to implement new ways of thinking about your tech stack, there are always going to be challenges. Implementing a thorough strategy of application observability is no different.
Here’s what you should watch out for and how you can overcome the challenges in your technology:
Data Silos: Many organizations face challenges due to data silos, where information is isolated within specific teams or tools. Implementing observability requires breaking down these silos through cross-team collaboration and shared platforms.
Complexity: As systems grow in complexity, so do the challenges in observability. Interconnected systems monitored by your tools can get complicated and break. Organizations need to adopt scalable solutions and invest in the necessary training to manage this complexity effectively.
Cost Concerns: Implementing observability tools may come with associated costs, most often driven by rising data volumes. If data and costs rise too sharply, the long-term benefits, such as improved performance and reduced downtime, often outweigh the initial investment. You must ensure that your tools are set up to collect the data you need, and also employ capabilities that reduce unneeded data that will drive up costs.
Resistance to Change: Teams may resist adopting new observability practices. Effective communication and training are essential to overcoming this resistance and ensuring a smooth transition.
Automating AIOps and DevSecOps
Automation plays a crucial role in both AIOps (Artificial Intelligence for IT Operations) and DevSecOps (Development, Security, and Operations). Application observability acts as a cornerstone in these frameworks by providing real-time data that can be leveraged by automated processes.
In AIOps, automation is used to identify patterns, detect anomalies, and even initiate corrective actions without human intervention. This enables organizations to respond rapidly to dynamic changes in their IT environments.
DevSecOps integrates observability into the software development lifecycle, ensuring that security considerations are seamlessly woven into every stage. By automating security checks and monitoring, organizations can deliver secure and reliable applications at a faster pace.
Ongoing integration with widely available generative AI and Large Language Models (LLMs) is rapidly serving to accelerate and deepen the power and context of observability tooling.
The Future of Application Observability
As we look to 2024 and beyond, several trends and directions are shaping the future of application observability:
AI-driven Observability: Artificial intelligence will play an increasingly significant role in analyzing vast amounts of observability data, identifying patterns, expanding contextual analysis and predicting potential issues.
Edge Computing Observability: With the rise of edge computing, observability will need to extend beyond traditional data centers to monitor and manage applications at the edge.
Increased Integration: Observability will become more tightly integrated into the software development lifecycle, with tools seamlessly embedded into CI/CD pipelines.
Focus on Security Observability: Security observability will gain prominence as organizations prioritize the identification and mitigation of security threats through observability practices.
Standardization Efforts: The industry will witness efforts to standardize observability practices, making it easier for organizations to adopt and implement these tools across different platforms.
Initiating Your Journey with Logz.io Application Observability Tools
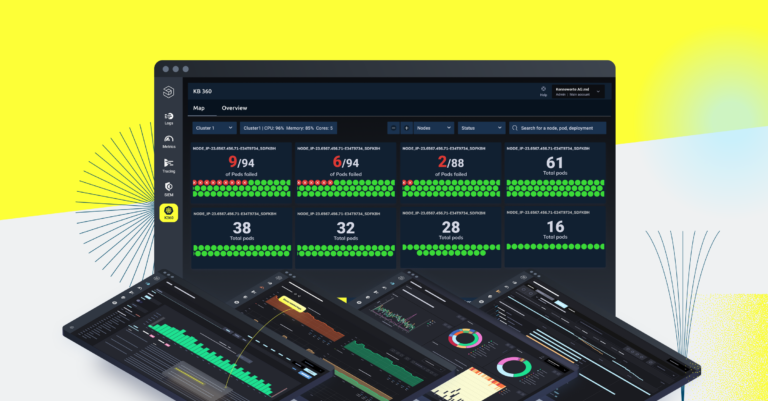
Logz.io stands out as a leading provider of a unified, “full stack” approach enabling a more effective strategy for application observability. This is delivered through the Open 360™ observability platform, which provides software developers, SREs and operations pros the specific tools they need to unify logs, metrics and trace data in one location for a conclusive, end-to-end view of system behavior.
Open 360 also delivers a modern, observability-centric approach analyzing the health and performance of applications, as an alternative to traditional application performance management (APM), in the form of the App 360 solution.
With App 360, a strategic set of capabilities unified in the Open 360 platform, users get a centralized interface for visualizing and investigating application performance, without many of the technical challenges and high cost associated with traditional APM solutions. Automated data collection based on OpenTelemetry further simplifies and accelerates related processes.
App 360 is purpose-built for distributed microservices architectures running on Kubernetes and other modern environments, and enables stakeholders to visualize and investigate the most important right signals, while correlating all the relevant information to truly understand their environment from individual applications all the way down to the CPU level. The solution is complemented by our Kubernetes 360 solution for managing related infrastructure metrics.
With Logz.io, you’ll avoid siloed telemetry and quickly achieve full application observability so you can answer difficult questions about the current state of your environments — at a fraction of the cost of other platforms.
Logz.io’s approach combines the strengths of observability and APM, allowing organizations to gain deep insights into application performance while also exploring the broader context of their IT environment.
Conclusion
As the digital landscape continues to evolve, application observability stands out as a crucial practice for ensuring the reliability, performance, and security of modern applications. By adopting observability tools and practices, organizations can gain deeper insights into their systems, proactively address issues, and deliver exceptional user experiences.
As we venture into 2024, the future of application observability looks promising, with advancements in AI, edge computing, and increased integration shaping a new era of IT and software development.
If you’d like to see App 360 yourself, in action, sign up for a free trial of Logz.io Open 360 today.

You Might Also Like

5 Important Reasons Why You Need Application Observability
