
Challenge Met: Adopting Intelligent Observability Pipelines
October 24, 2023
Over the last year or so, the unavoidable topic of overwhelming cost has emerged as the number one issue among today’s observability practitioners.
Whether it is in conversations among end users, feedback from customers and prospects, industry chatter or the coverage of experts including Gartner, the issue of massive telemetry data volumes driving unsustainable observability budgets prevails.
In some cases, the matter has even resulted in somewhat comedic outcomes, such as the notorious cryptocurrency darling whose carefree spending generated an eight-figure observability bill that represents 2-3 times its current market cap. Such outrageous examples aside, driving down observability cost has now elevated to the level of the boardroom as it has become a primary component of cloud budgets, full stop.
Interestingly, when we started asking experts about this topic as far back as 2021, their initial response was that teams using traditional APM and observability tools weren’t that concerned. The notion was that since someone else was footing the bill from the standpoint of budgeting, the DevOps teams, engineers, SREs et al with their hands in the data were more concerned about gaining useful insights.
However, driven by continued scrutiny of all budgets and the reality of staggering observability data volumes generated by sprawling CI/CD-driven, Kubernetes-centric cloud architectures, the pendulum has undoubtedly swung. The cost issue is now unavoidable.
Too Much of a Good Thing Drives Innovation
As our CEO Tomer Levy pointed out in his “observability is broken” call to action earlier in 2023, the primary concept is that legacy monitoring practices never fully evolved to meet the realities of the observability world. The “ship and save everything” approach doesn’t scale to fit the modern cloud applications environment.
From the amount of work needed to sort through and prioritize all the involved telemetry to the intentionally-predatory licensing of entrenched APM vendors, no one was really looking at the issue, until it ballooned out of control. Then it did. So now what?
If necessity is the mother of all invention, then a looming recession is the agitator of real action. Somewhere over the last 12-16 months we reached a tipping point, and that’s where the approach of intelligent, AI-backed observability data pipelines came into focus. Along with many others, as well as folks like Gartner, we believe this holds the potential for solving today’s biggest observability ills.
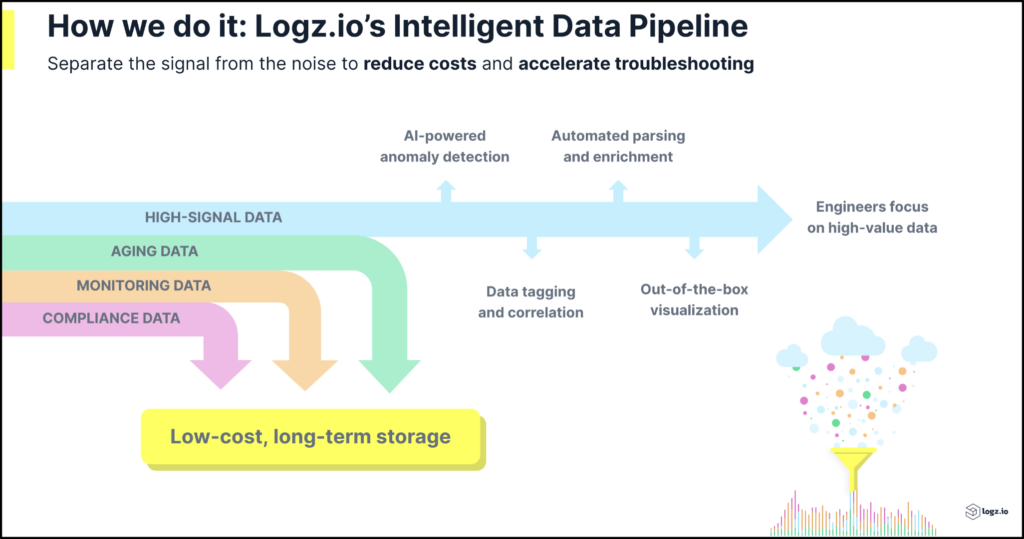
Now, instead of sending everything to the platform for ingestion, maintaining massive log repositories for ongoing analysis, and keeping everything in hot or even warm storage, people have come around to the idea of taking a close eye to practical data values and applying pipeline analytics to better prioritize and budget their data.
If you want to read a hugely insightful deep dive on this topic check out the “Innovation Insight: Telemetry Pipelines Elevate the Handling of Operational Data” report by Gartner VP Analyst Gregg Siegfried. One of his biggest takeaways is that by 2026, nearly half of all telemetry will be processed through an advanced pipeline of some sort, an increase of 4-5 times compared to present.
Logz.io is an Observability Pipeline Leader
Perhaps it is the nature of the organizations that we deal with, many of which are 100% all cloud, all-the-time software disruptors, but Logz.io saw this moment coming years ago and started building observability pipeline capabilities to address it.
The reality is that we’ve always taken a high data quality approach, providing tools such as our Drop Filters to help customers control data volumes and costs, along with multi-tiered storage to ensure that they maintain platform data as efficiently as possible.
In 2022, we announced our Data Optimization Hub, an even more advanced, AI-driven approach founded in intelligent observability pipeline analytics. Using this unique capability, squarely-focused on enabling our customers to identify and de-prioritize high-volume, low-value telemetry, we found organizations could reduce their costs by an average of 32%. As it turns out, our own results were even higher.
And we continue to evolve this approach, driven by customer and industry feedback. Today, complemented by adjacent features such our LogMetrics capabilities (translate high volume, lower value logs into potent metrics) and Cold Tier (maintain lesser value data in S3 for lower cost, without significantly sacrificing availability), our data pipeline specifically empowers customers to:
- Segregate data based on its specific use case
- Optimize costs per data type and analysis requirements
- Maintain their most important data for troubleshooting
- Eliminate unnecessary data that will never be used
- Evolve data storage over time to suit changing needs
Whether you’re just coming around to the topic of bloated observability budgets or you were singing this song along with us several years ago, we hope you’ll agree that Logz.io Open 360™ offers one of the most innovative observability pipelines available.
To get started, start a Logz.io free trial and begin sending telemetry data to your new account. From there, just open up Data Optimization Hub to automatically get a full inventory of your incoming data, along with filters, LogMetrics, and rollups to optimize your data volumes and reduce costs.

You Might Also Like

Logz.io Named Visionary in 2023 Gartner® Magic Quadrant™ for Application Performance Monitoring and Observability

