
The Removal of Mapping Types in Elasticsearch 6.0: The Aftermath
January 15, 2018

As you may have already heard, the recent release of Elasticsearch 6 signaled the beginning of the end to the concept of mapping types. Defined as a breaking change, and relating to the core functionality and usage of Elasticsearch, this change was somewhat controversial. Some users even went as far as viewing this change as a “casus belli” of sorts.
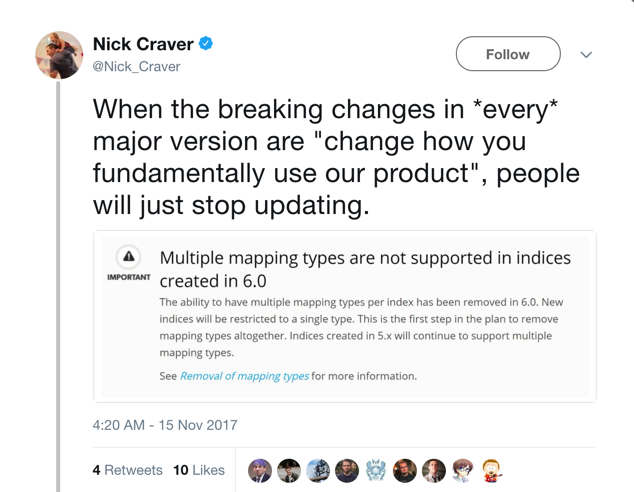
While there is little doubt that the removal of types has huge implications for Elasticsearch users, it is important to chill the atmosphere by understanding the reasons for this move and its meaning as well as ways to adapt to it.
What are Elasticsearch mapping types?
Let’s begin with trying to understand what mapping types are and how they were used up until now.
Within Elasticsearch, mapping defines how a document is indexed and how its fields are indexed and stored. Each Elasticsearch index had one or more mapping types that were used to divide documents into logical groups. In other words, a type in Elasticsearch represented a class of similar documents.
Comparing to the world of relational databases (a problematic comparison that we will get to later in the article), types can be compared with tables.
Let’s say we are indexing different types of students (e.g. honor students, failing students, etc.)
The mapping type for such an index would consist of a combination of fields as seen in this example:
curl -X PUT 'http://localhost:9200/students' -d '{
"mappings": {
"student": {
"properties": {
"name": { "type": "keyword" },
"degree" { "type": "keyword" },
"age": { "type": "integer" }
},
"properties": {
"performance": { "type": "keyword" }
}
}
}
}'
The index would then be built with a _type field which was combined with the document’s _id field to generate a _uid field, allowing documents of different types to co-exist in the same index.
So to index a new student, we would use:
curl -X PUT 'http://localhost:9200/students/student/1' -d '
{
"name" : "Isaac Newton",
"age": 14,
"performance": "honor student"
}'
And when querying Elasticsearch for a student, we would use the mapping type by including it in the URL:
curl -X GET 'http://localhost:9200/students/student/_search' -d '
{
"query": {
"match": {
"name": "Isaac Newton"
}
}
}'
This kind of search would return:
{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"skipped":0,"failed":0},"hits":{"total":1,"max_score":0.51623213,"hits":[{"_index":"students","_type":"student","_id":"1","_score":0.51623213,"_source":
{
"name" : "Isaac Newton",
"age": 14,
"performance": "honor student"
}}]}}
You can read more about Elasticsearch mapping types here.
So, why are mapping types being removed?
Looking back in time to an issue opened in 2015 on the Elasticsearch GitHub page gives us insight into the main reason mapping types are being removed—to simplify the understanding and usage of the underlying data structure in Elasticsearch and to optimize performance.
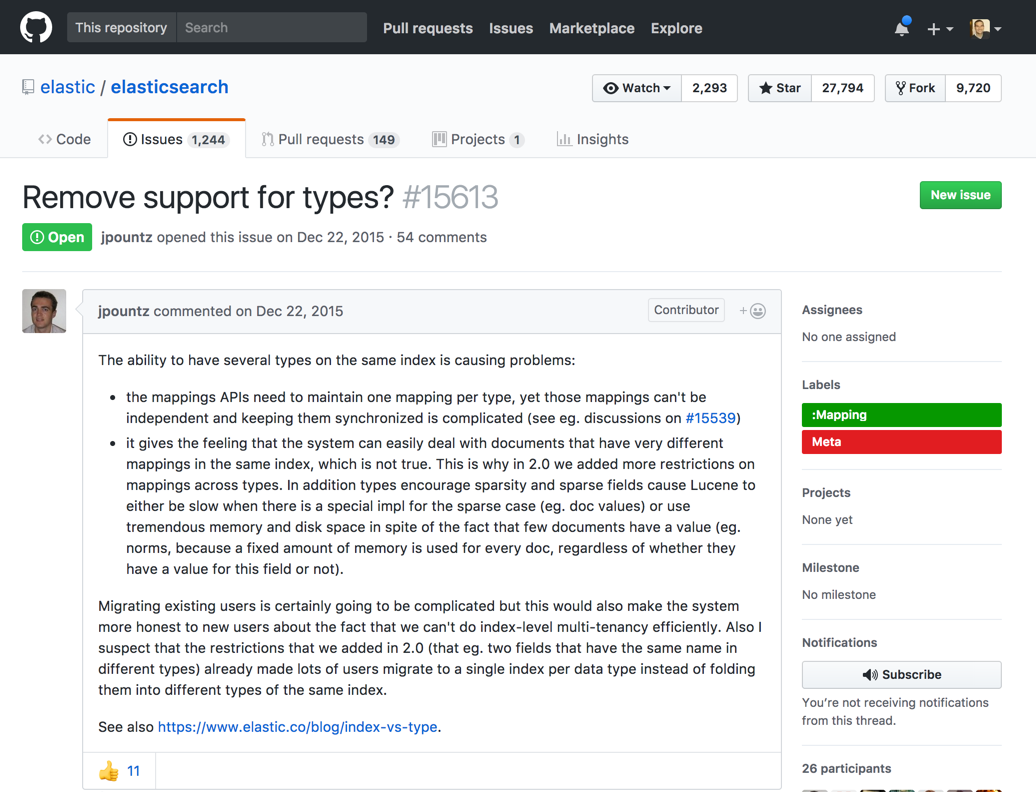
When trying to understand or explain the data structure Elasticsearch is based upon, users often referred to a comparison with relational databases, where: index = database, type = table.
While there is a certain logic to this analogy, it is simply incorrect from a technical standpoint.
Unlike SQL databases, where tables are totally independent from each other, and where columns in different tables do not affect one another, Elasticsearch fields and mapping types in the same index are interrelated.
Fields that share the same name but are used in different mapping types are backed by the same Lucene field. This means, in turn, that fields with the same name, and which are used in different types within the same index, must have the same mapping definition—a constraint that can be extremely limiting in some scenarios.
If we wanted to use the performance field name in another type within the same index, it would have to have the same mapping definition as defined in the students type:
curl -X PUT 'http://localhost:9200/students' -d '{
"mappings": {
"student": {
"properties": {
"name": { "type": "keyword" },
"degree" { "type": "keyword" },
"age": { "type": "integer" }
},
"properties": {
"performance": { "type": "keyword" }
}
}
"teacher": {
"properties": {
"name": { "type": "keyword" },
"degree" { "type": "keyword" },
"age": { "type": "integer" }
},
"properties": {
"performance": { "type": "keyword" }
}
}
}
}'
The second issue is related to how Lucene handles documents with empty fields (field with no value), an issue otherwise known as data sparsity. Multiple types in the same index results in most cases in a large amount of empty fields, which because of the way Lucene stores data, results in suboptimal resource utilization.
Using types in Elasticsearch 6
We can start with the good news, which is that types have not been totally removed. Yet.
Multi-Type Index to Single-Type Index
While indices created in version 6 are only allowed one mapping type, indices created in version 5 containing multiple types can continue to work as before. You can also use the Elasticsearch ReIndex API to convert these indices to single-type indices.
To achieve the same functionality in Elasticsearch 6, what alternative methods are there?
Other than the obvious method of placing all your properties under one single type, there are two additional methods for accomplishing the same goal achieved with multiple mapping types in previous Elasticsearch versions.
The first is to have an index per document type. In our example, you could put honor students in one index, failing students in another index, and so forth for each type of student.
Another solution is to create a custom type field which works pretty similarly to how the good old _type meta-field worked:
curl -X PUT -H "Content-Type: application/json" 'http://localhost:9200/students' -d '
{
"mappings": {
"doc": {
"properties": {
"type": { "type": "keyword" },
"name": { "type": "text" },
"age": { "type": "integer" }
}
}
}
}'
Continuing with our previous example, we can populate this field with some data:
curl -X POST -H "Content-Type: application/json" 'http://localhost:9200/students/doc/1' -d '
{
"type": "honor student",
"name": "Isaac Newton",
"age": 14
}'
So to search for our honor students, we would use:
curl -X GET -H "Content-Type: application/json" 'http://localhost:9200/students/_search' -d '
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"term": {
"type": "honor student"
}
}
}
}
}'
Version 6.x also uses the temporary include_type_name parameter as part of a transition phase. This will default to true in version 6.x.
Using types in Elasticsearch 7
In the past, you world define parent types and child types by nesting one type under another. It has been replaced with the join field.
Just as indices created with in version 5 worked in version 6 as they had in version 5, indices made in version 6 will continue to work the same way in version 7. In other words, that index doesn’t have to be redone to meet the new standard. But indices created in version 7.x will not accept a _default_ mapping.
Type specification is completely deprecated in 7.x. _doc is not a document type, but an endpoint name—it’s also a permanent part of the document path.
Index API paths are now the following:
For exact IDs:
PUT {index}/_doc/{id}
and for automatically-created IDs:
POST {index}/_doc
Version 7.x also uses the temporary include_type_name parameter as part of a transition phase. This will default to false in version 7.x.
Typeless document APIs only become available with 7.x, so won’t work with 6.x releases of Elasticsearch.
Using types in Elasticsearch 8
Version 8.x is scheduled to deprecate the temporary include_type_name parameter.
Types are entirely removed from responses by version 8.x.
Remember to keep track of mixed versions of Elasticsearch in your clusters.
Summing it up
The removal of mapping types is a process that started already in version 5, has been taken a serious step further in step 6, and is planned to continue in the next versions until the complete removal in version 9 (stay updated, and take a look at the planned changes here).More on the subject:
Breaking changes are always a pain, especially fundamental changes that require rethinking the way we operate, but at the end of the day, the end game is all that matters. While indeed a breaking change in any Elasticsearch index with multiple types, it also seems to be an important change with obvious benefits in terms of ease-of-use and performance. Ultimately, forcing us to use indices in a way that is more suited to the underlying data structure should speed up searches.
It seems that most users tend to agree with this assertion:

As we begin the migration process to Elasticsearch 6, we will document and report any issues we come across in respect to this change, so stay tuned for news.

You Might Also Like

Transform Troubleshooting with Logz.io’s AI Agent

