
Logz.io’s Prometheus-as-a-Service is Generally Available
March 16, 2021

Today, Logz.io is thrilled to announce that Prometheus-as-a-service is now generally available for anyone to try themselves! I’d like to thank the Logz.io village for executing a huge milestone on our quest to unify the best open source monitoring tools on Logz.io’s scalable cloud platform.
Prometheus-as-a-service is the core pillar of our Infrastructure Monitoring product, which makes it easy for teams to centralize and analyze their metrics, and configure alerts to monitor for production issues.
Prometheus: Simplified and Unified.
From our conversations with hundreds of DevOps teams, it’s clear that Prometheus is the de facto starting point for cloud monitoring. It’s easy to implement and integrate with distributed environments. But we’ve also heard these repeating experiences among Prometheus users:
- Modern Prometheus deployments that store large volumes of metrics for long periods of time can be complex. This can create unwelcome management overhead costs for time-squeezed teams.
- Prometheus is a dedicated metrics monitoring solution. For teams that also need to monitor their logs and traces for full observability, they’ll need separate and siloed tools. This means more systems to manage and disconnected or slower troubleshooting.
Prometheus-as-a-service centralizes your Prometheus metrics on Logz.io’s scalable cloud platform for storage and analysis. Teams can continue using their existing Prometheus metrics scraping capabilities, while eliminating the burdens of metrics storage and siloed monitoring data.
Migrating to Logz.io’s Prometheus-as-a-service is simple. Just add a few lines of code to your Prometheus config files to begin sending your prometheus metrics to Logz.io. This will effectively offload the management of storing your Prometheus data, while unifying your metrics with log and tracing analytics. You can also easily import your existing Grafana dashboards to Logz.io.
To compliment the easy transition from Prometheus to Logz.io, we hope our changed Infrastructure Monitoring plans makes migrating your metrics management and analytics to Logz.io an even easier decision.
Try it for yourself with our free trial – learn how to send your Prometheus metrics to Logz.io with our documentation or this tutorial video. For every trial account that sends Prometheus metrics to Logz.io within 2 months from now, we’ll donate $15 to the Linux Foundation.
See the video below for a quick demo on how it works, how it simplifies your monitoring operations, and how to get started:
Remove the burden of managing Prometheus with just a few lines of code
Most DevOps teams start using Prometheus at small scales to monitor a few key services, which is relatively easy to do.
But as teams add more services and want greater visibility into their environment, they need more Prometheus servers to collect higher volumes of metrics.
On top of that, teams require long-term metrics storage to monitor the operational health of services over time.
To collect and store high volumes of metrics for long periods of time, engineers will need more Prometheus servers, and even roll up servers – which condense metric data by taking averages. The result can be a daunting pyramid of Prometheus servers that each require monitoring (yes, you should to monitor your monitoring solution), upgrading, data replication for HA, and other maintenance tasks that can be difficult to track and complete.
The overhead costs of managing modern Prometheus deployments can distract DevOps teams from other core responsibilities. And this is where Prometheus-as-a-service comes in.
Get Started with Prometheus-as-a-Service in Minutes
Prometheus-as-a-service removes the burden of managing metrics storage, while also allowing you to keep your current Prometheus deployment in place. This means you can keep your current Prometheus metrics scraping as it is, and leave the data storage and analytics to us.
To begin sending your Prometheus metrics to Logz.io, simply add ‘remote write’ to your configuration files. Remote write makes it easy to forward your Prometheus metrics to a remote destination, like Logz.io.
remote_write:
- url: https://<<LISTENER-HOST-URL>>:8053
bearer_token: <<PROMETHEUS-METRICS-SHIPPING-TOKEN>>
remote_timeout: 30s
queue_config:
batch_send_deadline: 5s #default = 5s
max_shards: 10 #default = 1000
min_shards: 1
max_samples_per_send: 500 #default = 100
capacity: 10000 #default = 500
After creating a Logz.io Infrastructure Monitoring account, you’ll get a listener host URL and metrics shipping token. Just add these parameters to the code block above and paste it into your Prometheus config files. Soon after, you’ll begin to see your Prometheus metrics stream into Logz.io.
This means you don’t need to store metrics in your own Prometheus time-series database for more than a few hours. At that point, you effectively offload the management burden of storing your own data. Leave that to our scalable cloud service.
Unifying the Best-of-Breed Open Source for Logs, Metrics & Traces
Prometheus has quickly become the de facto starting point for DevOps teams starting their cloud monitoring journey. As mentioned, it’s easy to implement and integrate with distributed cloud workloads. The figure below shows its quick adoption among the DevOps community.

Source: DB-Engines Ranking – Trend of Prometheus Popularity
While thousands of engineers use Prometheus to collect metrics and identify production issues, they’ll also likely need logs and traces to offer a complete triangulation of what’s causing those issues. Plus, if they’re also using open source to collect or analyze both their logs and traces, they’ll need to deal with the overhead of managing those solutions as well.
In short, complete observability should be seen as a single job, so it shouldn’t require multiple tools.
Logz.io unifies the best open source tools for metrics, logs, and traces – ELK, Prometheus, and Jaeger – onto a scalable cloud platform.
This means you can immediately correlate your metrics with their associated logs and traces for a fuller picture of what is causing production issues.
You can also monitor your logs in the same UI as your metrics to quickly understand how specific events impact your metrics.
Check out how quickly we found the relevant logs that explain what’s causing these spiking pod memory metrics…

…or how we explored the trace that shows the microservice operation responsible for the spiking latency.
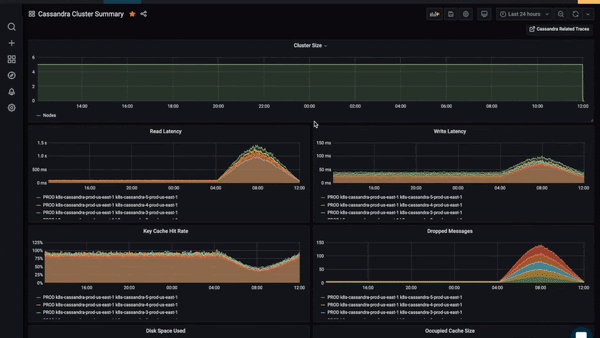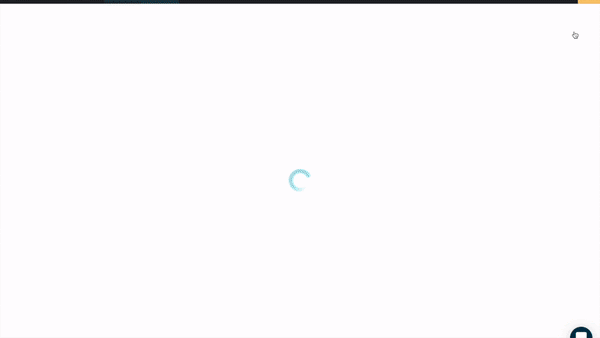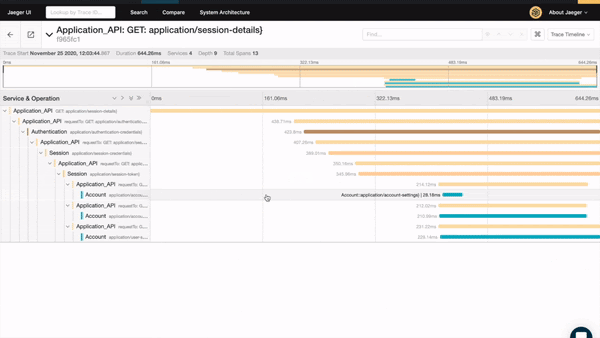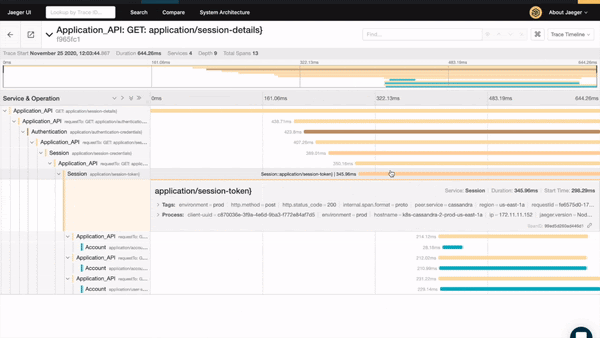
When all of your data is together, you’ll be able to find the relevant information faster.
And of course, you can say goodbye to managing multiple open source systems for monitoring and observability. That’s all handled by Logz.io’s SaaS platform.
Prometheus is great for collecting metrics – but what about analyzing them?
Many Prometheus users collect and store their metrics with Prometheus, and analyse those metrics with Grafana. Prometheus and Grafana are a match made in heaven, and we wouldn’t want all the hard work of creating Grafana monitoring dashboards to go to waste. That’s why we made it easily to import your existing Grafana dashboards to Logz.io’s metrics analytics interface.
Simply upload your Grafana dashboards as JSON files to Logz.io and hit ‘Load’ to see your dashboards in Logz.io’s metrics UI.

Once you’ve imported your dashboards, you can visualize and analyze your metrics. Improve your dashboards by:
- Editing and customize visualizations with PromQL and data filters
- Adding links to correlate metrics with the associated logs or traces.
- Configuring alerts to trigger notifications to Slack, PagerDuty, or whatever you’re using to consolidate your alerts.
- Adding dashboard annotations to overlay logged events on metrics visualizations.
Next steps
Prometheus-as-a-service eliminates the burden of managing Prometheus servers and data yourself, while unifying your metrics with logs and traces.
If you want to step up your cloud monitoring and observability while continuing to use the monitoring technology you know, sign up for our free trial to see whether it’s the right option for you.

You Might Also Like

Modern Observability 101

