
Role-Based Access, S3 Archiving & Fluentd with Logz.io’s ELK
August 13, 2015
Following our addition of alerts on top of the ELK Stack, the positive feedback that we received from the community made it clear that we should continue to enhance those platforms with additional features that people would like to see.
In this post, I’d like to introduce three new features that we have just released and explain how they are integrated throughout the ELK Stack.
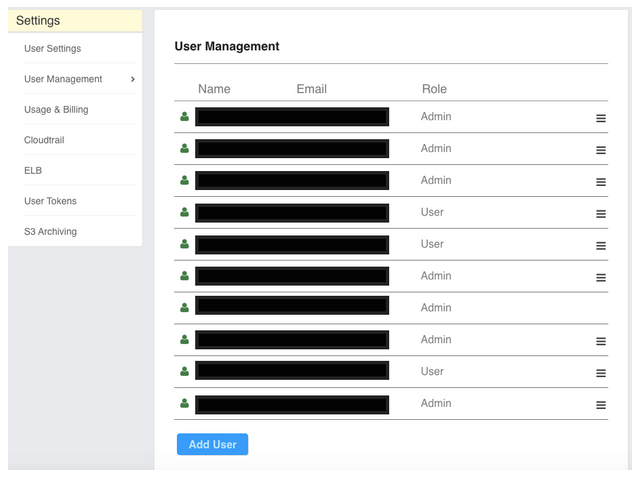
Multi-User and Role-Based Access
The most important thing about properly integrating a platform such as ELK is the ability to share the knowledge and functionality within one’s organization. The open source ELK Stack comes with a very limited single-user approach, which in our mind was a huge gap and interfered with usability and adoption.
More on the subject:
Since we’ve added the multi-user and role-based access features, we have noticed that our Pro customers have been averaging around 30 users on a single account, transforming the way our customers are using ELK.
To define multiple users in Logz.io, you can go to your Settings tab and click on the “User Management” tab. You can then define as many users as you want, and they will receive invitations over e-mail to join your Logz.io account and enjoy the power of the ELK Stack as a service.
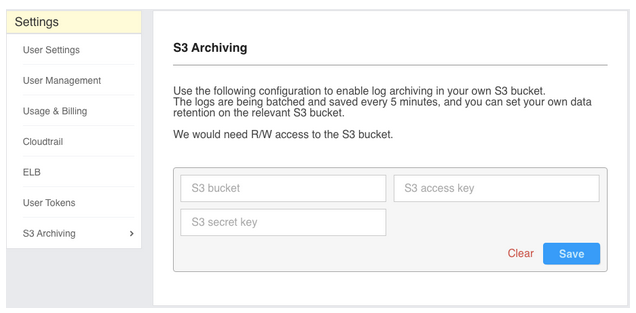
Archiving to S3
 Many of our customers have requirements to retain their logs for compliance purposes, sometimes for as long as several years. These organizations, however, didn’t have a requirement to keep the logs searchable at all times, so it was important for us to provide a solution for them that will satisfy their compliance needs as well as remain a cost-effective solution.
Many of our customers have requirements to retain their logs for compliance purposes, sometimes for as long as several years. These organizations, however, didn’t have a requirement to keep the logs searchable at all times, so it was important for us to provide a solution for them that will satisfy their compliance needs as well as remain a cost-effective solution.
At Logz.io, we employ a real-time backup process designed to safeguard customers’ information. With this latest release, we now also enable customers to store all of their log files into an Amazon S3 bucket automatically and determine on their own what would be the retention period and cost associated with it.*
The logs are being archived in zipped files which include JSON formats. At any time, a user can manually search through the files or re-ingest these events with Logz.io.
In order to enable the archive to S3, we need an R/W permission into an S3 bucket of your choice. Go to the Settings page under “S3 Archiving” and enter your bucket name and credentials. We store the incremental data every few minutes, and you can set the retention on that bucket and the cost by controlling the redundancy.
*S3 archiving is only available for our Pro customers.
Connectivity to Fluentd
 With the growing popularity of fluentd and the resulting demand from our customers, it was important for us to enable the link between Fleuntd and the ELK Stack. Fluentd today has an output plugin to Elasticsearch, but if you want to leverage the power of Logstash as well, it’s challenging to make the connection. We have implemented an output plugin that ships logs directly to Logz.io and provides all the benefits of the ELK Stack as a scalable and secure service.
With the growing popularity of fluentd and the resulting demand from our customers, it was important for us to enable the link between Fleuntd and the ELK Stack. Fluentd today has an output plugin to Elasticsearch, but if you want to leverage the power of Logstash as well, it’s challenging to make the connection. We have implemented an output plugin that ships logs directly to Logz.io and provides all the benefits of the ELK Stack as a scalable and secure service.
Our github repository contains instructions on how to set up the Fluentd logz.io output plugin. If you have any questions, please feel free to ask!
The ELK Stack is a wonderful platform, and we’re always trying to make it even better. If there are any features that you would like to see in ELK, just drop us a note at info (at) logz.io! We always look forward to receiving feedback from the community.

You Might Also Like

Top 10 Mistakes People Make When Building Observability Dashboards

