
A Guide to the World of Cloud-Native Applications
June 25, 2019

It all started with monolith architecture; business logic, user interfaces, and data layers were stored in one big program. As tightly coupled applications, a simple update to the program meant recompiling the entire application and redistributing the program to all users. That led to the difficulty of maintaining consistent program versions and distribution across all clients in order to ensure stability and alignment. This made the monolith approach inefficient and cumbersome. More on the subject:
In the Internet era, Web 2.0 applications that run on the server side are typically deployed in a three-tier web application (Model-View-Controller architecture, or MVC). This approach solves most monolith architectural problems, including uniformity across users and code maintainability. However, as businesses now require faster time to market, transactions are growing to petabytes of data, and Dev teams are integrating with Ops teams. This has led to the formation of a new design paradigm, called “cloud native,” to address these changes.
So what exactly is “cloud native?” In this article, we’ll discuss the term in more detail, and explore several key features of cloud-native applications.
What Is Cloud Native?
It is important to note that applications running in the cloud are not necessarily cloud native. For that matter, a direct lift and shift from on-premises to the public cloud does not take full advantage of the cloud’s benefits. In fact, an application running on-premises or a private cloud may still be cloud native if it meets certain sets of properties and standards (discussed in the following section).
Cloud native is like the citizenship of an application. A Marvel character may appear in a DC Comics book, yet remain a Marvel superhero. The same concept applies to a cloud-native application. Nobody invented cloud native; rather, it is a design paradigm closely governed by the Cloud Native Computing Foundation (CNCF). CNCF fosters a community around a group of high-quality projects and builds sustainable ecosystems that orchestrate containers as part of a microservices architecture.
Cloud-native applications can be defined technically as applications running in a containerized environment, capable of moving in and out of the cloud, that scale horizontally based on varying workloads. They are deployed as microservices, abstracted to underlying infrastructure, and delivered through a DevOps pipeline. Often, cloud-native applications are orchestrated by Kubernetes, a command center for containers, which was developed by Google and forked from their proprietary orchestrator named Borg. Let’s dig deeper and find out what makes a cloud-native application.

Key Features of a Cloud-Native Application
1. Containerized
To be considered cloud native, an application must be infrastructure agnostic and use containers. Containers provide the application with a lightweight runtime, libraries, and dependencies that allow it to run as a stand-alone environment able to move in and out of the cloud—independent of the nuances of a certain cloud provider’s virtual servers or compute instances. With this, containers are able to increase mobility between different environments. According to last year’s Forrester report, the industry leader in container technology is Docker.
2. Microservices
The term “microservice” is a design paradigm used in cloud-native applications to break down large components into multiple stand-alone deployable parts.
Take a human resources system. Previously, a system like this would have been deployed in one big package (e.g., a WAR file that used an MVC framework). By using a microservice, rather than deploying the human resource component as one big chunk, the component is divided and deployed into smaller functional units grouped by purpose (payroll, attendance, and employee microservices). This way, maintenance in the payroll module does not affect the other functionalities, since they can independently work on their own
3. Horizontal Scaling
A key property of cloud-native applications is the ability to horizontally scale in and out based on the size of their payload. It should be noted here that horizontal scaling is not through physical servers, but rather through Pods.
A Pod is a compute engine of container orchestrators, such as Kubernetes, that runs groups of containers. Each Pod has a dedicated set of CPU and memory allocation. Policies are used to determine whether to increase or decrease Pods. Stateless architecture means that cloud-native applications scale without a problem since data persistence or sessions don’t need to be maintained.
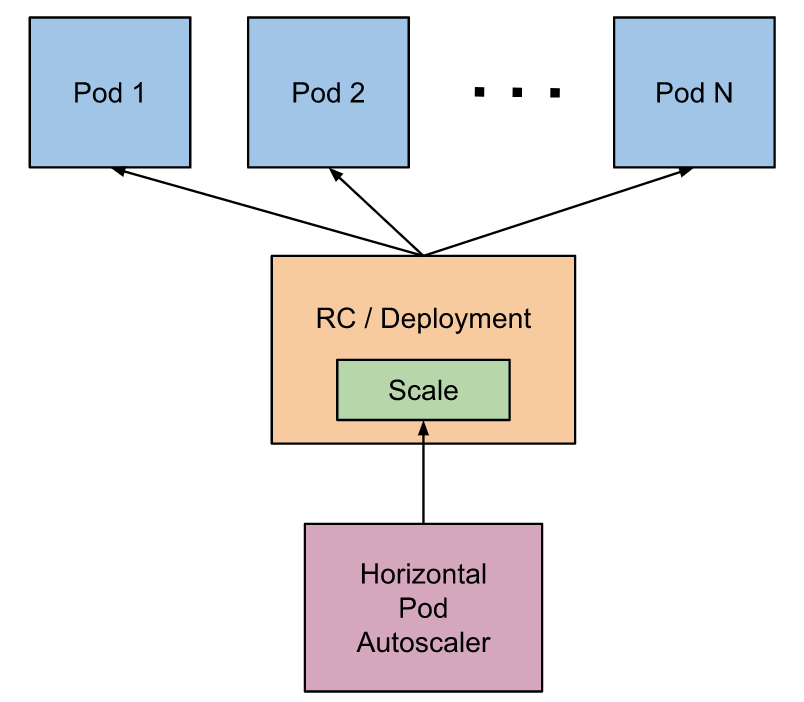
Scaling pods horizontally. Image Source
Sample Scaling Policy Pseudocode:
If CPU utilization > 60%
- Increase Pod by 1
If CPU utilization < 40%
- Decrease Pod by 1
Note: A Pod is not a virtual machine (VM), but rather “a single instance of an application in Kubernetes, which might consist of either a single container or a small number of containers that are tightly coupled and that share resources,” according to Kubernetes documentation
4. Service Mesh
Microservices can grow to hundreds, or even thousands, of interrelated services connected via an internal or external network. If we map out the connectivity of each microservice, complexity arises. Managing connectivity to these services at the code level is cumbersome. That would mean Service A would need to be aware of the network layer of Service B. To address this challenge, a technology called service mesh has been introduced.
William Morgan, CEO of Buoyant, provides a good definition of service mesh.
“A service mesh is a dedicated infrastructure layer for handling service-to-service communication. It’s responsible for the reliable delivery of requests through the complex topology of services that comprise a modern, cloud-native application. In practice, the service mesh is typically implemented as an array of lightweight network proxies that are deployed alongside application code, without the application needing to be aware.”
Istio is one of the leading open-source technologies for service mesh. According to Istio, in the simplest terms, “Service mesh connect, secure, and observe services.” Istio, a good example of commercial grade service mesh, is readily available on OpenShift and Pivotal, but requires some implementation work on Kubernetes.
5. API Driven
Microservices can grow complex, especially when building enterprise-scale applications. They also have to co-exist with either existing third-party applications or legacy programs. One way to ensure compatibility across platforms and simplify complexity is through API. The most common API used in the industry is RESTful API.
A RESTful API, also referred to as a RESTful web service, is based on representational state transfer (REST) technology, an architectural style and approach to communications often used in web services development. REST technology is generally preferred to the more robust Simple Object Access Protocol (SOAP) technology because REST leverages less bandwidth, making it more suitable for Internet usage.
So why is REST API used in cloud native? First, a REST API is a loosely coupled architecture. This enables microservices and user interfaces to communicate without dependencies. REST API also has a smaller footprint, so REST API responses use smaller bandwidths and are typically faster than SOAP API. This is ideal for cloud-native scalability. Second, being stateless by nature, microservices can be broken down into smaller pieces. Any errors in the API call can be reinitiated through endpoints. Lastly, future proof design is in the form of JSON or XML. Most, if not all, modern applications are capable of parsing the data.
6. Service Discovery
As we established, cloud-native applications make use of microservices. Each microservice has its own software-defined network that may or may not run on the same virtual computer (Pod). One microservice may need to communicate with another microservice, as seen in the below graphic: “withdraw” requires “checkbalance.”
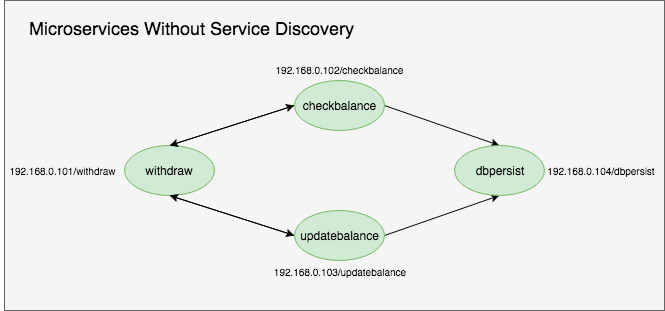
Without the service discovery capability, the microservice withdraw has to call checkbalance through an IP (e.g., 192.168.0.102/checkbalance). Imagine the burden on programmers and developers when we start talking about hundreds, or even thousands, of microservices. This is a potential maintenance and deployment nightmare because you would have to track all the IP addresses inside the code, as well as refactor in the event of an IP change or deployment to another environment.
Through service discovery, microservices don’t need to be aware of the network. Withdraw can invoke checkbalance through a simple URL HTTP endpoint (e.g., http://checkbalance). With service discovery, a cloud-native application can be ported to any environment without having to refactor the code.
7. Delivery Pipeline
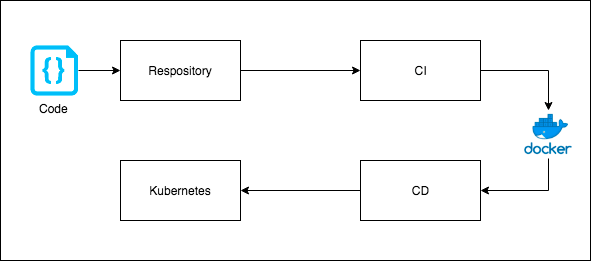
The modern software delivery pipeline is supported by Continuous Integration/Continuous Improvement (CI/CD), a practice to make deployment faster through application-release automation. CI/CD has the following components (see the diagram below):
- Codes are stored in a Repository (e.g., GITHUB).
- Each time a new code is pushed to a Repository, CI is automatically triggered to create a build (image). A build spec file contains all the information needed by Code Build to produce an image. The images are then stored in a Registry or Storage Bucket.
- Through CD, the environment is provisioned, and images are pulled from the registry for deployment.
- CD then pushes the image to the target environment (e.g., the Kubernetes cluster).
8. Policy-Driven Resource Provisioning
Cloud-native applications must be governed. Policy-driven resources allow applications to be isolated in the resource, namespace, and security layers. Quotas can be allocated to disk space, CPU, and memory to limit utilization, which is critical during horizontal scaling to prevent resources from becoming scarce.
According to Kubernetes documentation, “Kubernetes supports multiple virtual clusters backed by the same physical cluster. These virtual clusters are called namespaces. Namespaces are intended for use in environments with many users spread across multiple teams, or projects.”
Setting up namespaces presents a significant first degree of isolation between components. When different types of workloads are deployed in separate namespaces, it’s much easier to apply security controls such as network policies.
9. Zero Downtime Deployment
Downtime is not an option in modern applications, but deploying a new software version is often associated with downtime. To prevent this downtime, container orchestrators like Kubernetes have introduced the Zero Downtime deployment via the rolling update (see image below).
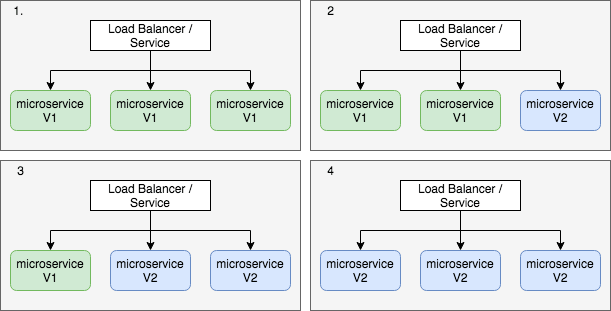
During a rolling update, the Pod running the microservice is removed from the available pool of resources by the load balancer. As soon as the microservice is ready, the Pod is rejoined to the pool by the load balancer, ready to accept traffic. The process is repeated until all versions are applied across all the Pods (see steps 1-4). This strategy effectively prevents downtime.
Summary: Three Considerations to Keep in Mind
Cloud-native strategy is more than just changing the title of an engineer from “Programmer” to “DevOps.” It requires the right people and processes, and depends on a cultural transformation. Consider the following tips:
- Retool Your Professionals: Retool staff with modern technologies and build champions in your organization. Technologies such as VMs and public cloud, modern programming languages, and design architecture are the basic training domains your organization needs.
- Move Your Cloud Journey Forward: Continue to move your workloads to the cloud, either private or public. Nominate non-critical monoliths or MVC applications to become early cloud migrants.
- Gear Towards Microservices: Refactor suitable applications to leverage key services in the cloud. Start building new applications, or update existing ones, by decoupling services into a multi-tier design.
To be cloud native, we believe you’ll need to re-architect not just your applications themselves, but also your dev and ops teams, your culture, and your processes. The journey to cloud native can be a long road, but you’ll find it rewarding in the end.

You Might Also Like

An Overview of the Essential Observability Metrics

