
Apache Flume and Data Pipelines
July 25, 2019

Introduction
Apache Flume helps organizations stream large log files from various sources to distributed data storage like Hadoop HDFS. This article focuses on the features and capabilities of Apache Flume and how it can help applications efficiently process data for reporting and analytical purposes. More on the subject:
What Is Apache Flume?
Apache Flume is an efficient, distributed, reliable, and fault-tolerant data-ingestion tool. It facilitates the streaming of huge volumes of log files from various sources (like web servers) into the Hadoop Distributed File System (HDFS), distributed databases such as HBase on HDFS, or even destinations like Elasticsearch at near-real time speeds. In addition to streaming log data, Flume can also stream event data generated from web sources like Twitter, Facebook, and Kafka Brokers.
The History of Apache Flume
Apache Flume was developed by Cloudera to provide a way to quickly and reliably stream large volumes of log files generated by web servers into Hadoop. There, applications can perform further analysis on the data in a distributed environment. Initially, Apache Flume was developed to handle only log data. Later, it was equipped to handle event data as well.
An Overview of HDFS
HDFS stands for Hadoop Distributed File System. HDFS is a tool developed by Apache for storing and processing large volumes of unstructured data on a distributed platform. A number of databases use Hadoop to quickly process large volumes of data in a scalable manner by leveraging the computing power of multiple systems within a network. Facebook, Yahoo, and LinkedIn are few of the companies that rely upon Hadoop for their data management.
Why Apache Flume?
Organizations running multiple web services across multiple servers and hosts will generate multitudes of log files on a daily basis. These log files will contain information about events and activities that are required for both auditing and analytical purposes. They can size up to terabytes or even petabytes, and significant development effort and infrastructure costs can be expended in an effort to analyze them.
Flume is a popular choice when it comes to building data pipelines for log data files because of its simplicity, flexibility, and features—which are described below.
Flume’s Features and Capabilities
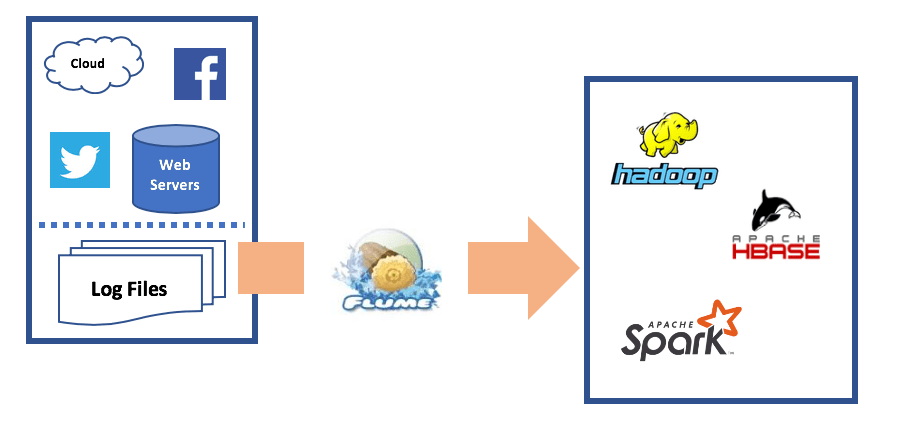
Apache Flume pulling logs from multiple sources and shipping them to Hadoop, Apache Hbase and Apache Spark
Flume transfers raw log files by pulling them from multiple sources and streaming them to the Hadoop file system. There, the log files can be consumed by analytical tools like Spark or Kafka. Flume can connect to various plugins to ensure that log data is pushed to the right destination.
Streaming Data with Apache Flume: Architecture and Examples
The process of streaming data through Apache Flume needs to be planned and architected to ensure data is transferred in an efficient manner.
To stream data from web servers to HDFS, the Flume configuration file must have information about where the data is being picked up from and where it is being pushed to. Providing this information is straightforward; Flume’s source component picks up the log files from the source or data generators and sends it to the agent where the data is channeled. In this process, the data to be streamed is stored in the memory which is meant to reach the destination where it will sink with it.
Architecture
There are three important parts of Apache Flume’s data streaming architecture: the data generating sources, the Flume agent, and the destination or target. The Flume agent is made up of the Flume source, the channel, and the sink. The Flume source picks up log files from data generating sources like web servers and Twitter and sends it to the channel. The Flume’s sink component ensures that the data it receives is synced to the destination, which can be HDFS, a database like HBase on HDFS, or an analytics tool like Spark.
Below is the basic architecture of Flume for an HDFS sink:

The source, channel, and sink components are parts of the Flume agent. When streaming large volumes of data, multiple Flume agents can be configured to receive data from multiple sources, and the data can be streamed in parallel to multiple destinations.
Flume architecture can vary based on data streaming requirements. Flume can be configured to stream data from multiple sources and clients to a single destination or from a single source to multiple destinations. This flexibility is very helpful. Below are two examples of how this flexibility can be built into the Flume architecture:
- Streaming from multiple sources to a single destination

In this architecture, data can be streamed from multiple clients to multiple agents. The data collector picks up the data from all three agents and sends it across to the destination, a centralized data store.
- Data streamed from a single client to multiple destinations
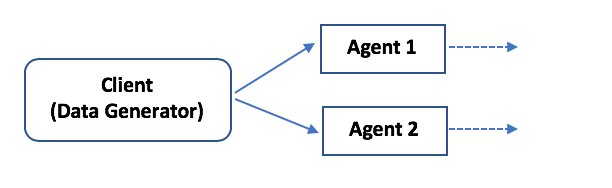
In this example, two Apache agents (more can be configured based on the requirements) pick up the data and sync it across to multiple destinations.
This architecture is helpful when streaming different sets of data from one client to two different destinations (for example, HDFS and HBase for analytical purposes) is necessary. Flume can recognize specific sources and destinations.
Integrating Flume with Distributed Databases and Tools
In addition to being able to stream data from multiple sources to multiple destinations, Flume can integrate with a wide range of tools and products. It can pull data from almost any type of source, including web server log files, csv files generated from an RDBMS database, and events. Similarly, Flume can push data to destinations like HDFS, HBase, and Hive.
Flume can even integrate with other data streaming tools like Kafka and Spark.
The examples below illustrate Flume’s integration capabilities.
Example 1: Streaming Log Data to HDFS from Twitter
As mentioned earlier, Flume can stream data from a web source like Twitter to a directory residing on HDFS. This is a typical requirement of a real-time scenario. To make this happen, Flume must be configured to pick up data from the source (source type) and sink the data to the destination (destination type). The source type here is Twitter, and the sink type is HDFS-SINK. Once the sink is done, applications like Spark can perform analytics on HDFS.
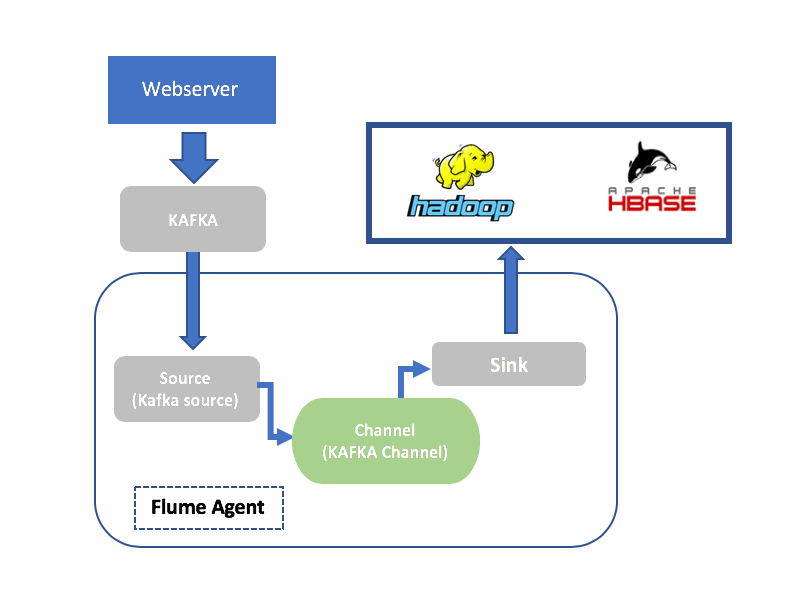
Example 2: Streaming Log Data from Kafka to HDFS Using Flume
Kafka is a message broker which can stream live data and messages generated on web pages to a destination like a database. If you need to stream these messages to a location on HDFS, Flume can use Kafka Source to extract the data and then sync it to HDFS using HDFS Sink.
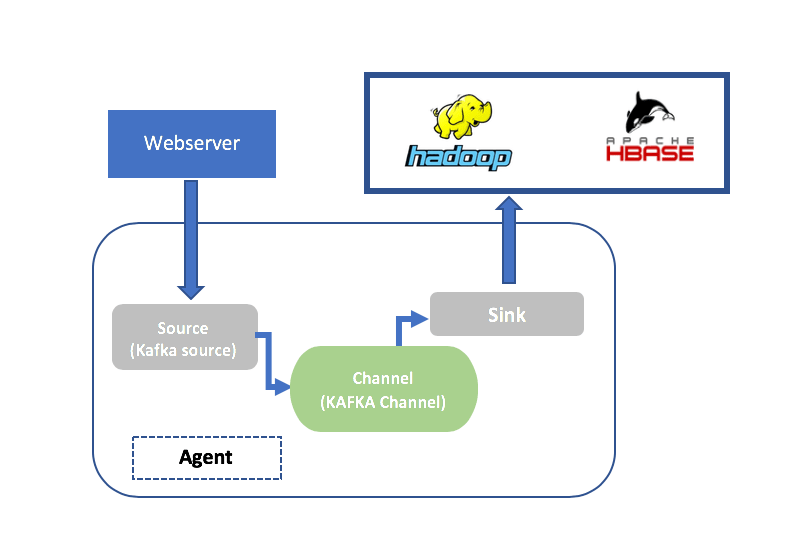
Streaming Log Data from Kafka to Hadoop (HDFS) Using Apache Flume
Example 3 : Streaming Log Data to Elasticsearch
Flume can be used to stream log data to Elasticsearch, a popular open-source tool which can be used to quickly perform complex text search operations on large volumes of JSON data in a distributed environment in a scalable manner. It is built on top of Lucene and leverages Lucene capabilities to perform index-based searching across JSON.
Flume can stream JSON documents from a web server to Elasticsearch so that applications can access the data from Elasticsearch. The JSON documents can be streamed directly to Elasticsearch quickly and reliably on a distributed environment. Flume recognizes an ELK destination with its ElasticsearchSink capability. Elasticsearch should be installed with a FlumeSink plugin so that it recognizes Flume as a source from which to accept data streams. Flume streams data in the form of index files to the Elasticsearch destination. By default, one index file is streamed per day with a default naming format “flume-yyyy-MM-dd” which can be changed in the flume config file.

Shipping logs via Apache Flume to Elasticsearch
The Limitations of Apache Flume
Apache Flume does have some limitations. For starters, its architecture can become complex and difficult to manage and maintain when streaming data from multiple sources to multiple destinations.
In addition, Flume’s data streaming is not 100% real-time. Alternatives like Kafka can be used if more real-time data streaming is needed.
While it is possible for Flume to stream duplicate data to the destination, it can be difficult to identify duplicate data. This challenge will vary depending upon the type of destination the data is being streamed to.
Summary
Apache Flume is a robust, reliable and distributed tool which can help stream data from multiple sources, and it’s your best choice for streaming large volumes of raw log data. Its ability to integrate with modern, real-time data streaming tools makes it a popular and efficient option.

You Might Also Like

2019 at a Glance: Logz.io Key Announcements

