
A Guide on Log File Parsing Tools
June 1, 2023

While log parsing isn’t very sexy and never gets much credit, it is fundamental to productive and centralized log analysis. Log parsing extracts information in your logs and organizes them into fields. Without well-structured fields in your logs, searching and visualizing your log data is near impossible.
In this article, we’ll review some of the more popular technologies for log file parsing so you can extract meaningful insights from your data.
The tools we will compare most often use the grok parsing language, which is unfortunately unintuitive, tedious, and often frustrating to use. For this reason, we’ll highlight some of the easier ways to get around grok, or at least to simplify it.
Comparing 5 popular log file parsing tools
As you’ll see in the list below, these are not standalone log parsing tools. Rather, they are log collection, processing, storage, and/or analysis tools, which also happen to have log file parsing capabilities.
Logging stacks can be complex, so most engineers prefer to combine parsing into an existing stage of the logging pipeline. Each of the technologies below have different sets of capabilities in addition to log parsing, so consider these when deciding on your log file parsing tool of choice.
Logz.io
Logz.io unifies logs, metrics, and traces for full observability in a single platform – which handles data collection, parsing, storage, and analysis at low-cost and low-maintenance.
Log parsing is just a small part of Logz.io’s feature set, which offers very simple ways to get your data parsed:
- Logz.io’s out-of-the-box parsing automatically parses common log types like Kubernetes, NGINX, Kafka, MySQL, and many other log types. You don’t have to do anything.
- For logs not supported by automatic parsing, simply reach out to Logz.io’s customer support engineers through the chat within the app. They respond within minutes and will parse your logs for you. We call it parsing-as-a-service.
- For those preferring to do it themselves, Logzio offers a self-service log parser that makes it easy to build and test your grok patterns before applying them.
For an overview of Logz.io’s log file parsing capabilities, see this video:
Logz.io is great for: those who want a fast way to parse their logs that requires minimal effort. Logz.io is a fully-managed log pipeline and analysis platform, so it’s quite a bit more than just log parsing.
Fluentd
Fluentd is a popular open source log collection and parsing tool best known for its native integration with Kubernetes. As a graduated member of the Cloud Native Computing Foundation, it is a very common component of modern logging stacks.
Fluentd has a number of plugins developed by the community that allow you to easily transform, route, and filter your log data. One of the plugin categories is called ‘Parser plugins’, which offers a number of ways to parse your data.
Like Logz.io, Fluentd offers prebuilt parsing rules. Below, for example, is Fluentd’s parsing configuration for nginx:
<source>
@type tail
path /path/to/input/file
<parse>
@type nginx
keep_time_key true
</parse>
</source>If your log types aren’t supported by Fluentd’s prebuilt parsing rules, you can use Fluentd’s grok parser plugin to implement your own grok parsing rules in Fluentd.
After implementing your Fluentd parsing plugin, it will collect and parse your logs before streaming them to your desired destination.
Fluentd is great for: those who need a free and lightweight log collection and parsing technology for cloud-native environments.
LogStash
While Logstash gets to claim the ‘L’ in the famous ELK Stack, it is hardly used in modern ELK implementations, because it is notoriously challenging to use and buggy.
Logstash has traditionally handled the log processing requirements of an ELK logging pipeline, but has since been replaced with far more simple and lightweight options like Fluentd or FluentBit. In addition to having log file parsing capabilities, these tools are much easier to use for log collection in distributed cloud environments.
Like Fluentd, data manipulation (such as parsing) in Logstash is performed using filter plugins. The most popular and useful filter plugin is the Logstash grok filter. Using grok filter, you can make Logstash add fields, override fields, remove fields, or perform other manipulations. Check out the full list of grok actions here.
Built-in, there are over 200 Logstash patterns for filtering items such as words, numbers, and dates. If you don’t find the pattern you need, you can use the tools below to build your own custom parsing pattern using the tools below:
- http://grokdebug.herokuapp.com – this is a useful tool for constructing and testing your grok filter on logs
- http://grokconstructor.appspot.com/ – another grok builder/tester
- https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns – a list of Logstash-supported patterns
- Logz.io Self-Service parser: as mentioned earlier, Logz.io’s Self-Service parser offers a simple way to build and test your grok patterns for Logz.io users.
For a deeper dive into Logstash, check out our comprehensive guide on Logstash log parsing.
Logstash is great for: nobody, except current Logstash users! If you’re a current Logstash user (there are many, which is why I included it in this article) and don’t want to replace it, the resources above can help you. Otherwise, I’d look somewhere else.
Vector
Maintained by Datadog, Vector is an open source observability data pipeline that collects, routes, and transforms your data. The three core components of Vector include Sources, Transforms, and Sinks. These components can be configured to collect data, manipulate it, and export it to a destination, respectively. When combined together, the components form a data pipeline called a Vector Topology.
For the purpose of this blog, we’re most interested in the ‘Transform’ component, which includes log parsing capabilities.
To get started with Transforms, you’ll have the options to make all kinds of changes to your observability pipeline, as you can see below.
For log parsing, we’re going to focus on the ‘remap’ option in the top left, which transforms data based on rules built in the Vector Remap Language.
VRL is the recommended method to parse logs with Vector. Like grok, it is an expression-oriented language aimed at extracting and organizing fields from log data. The VRL syntax is relatively simple to learn compared to grok and prevents the need to string together many Vector transforms to make basic changes to your data.
Below is an example of a VRL program from the Vector documentation. See the full list of parsing functions here.
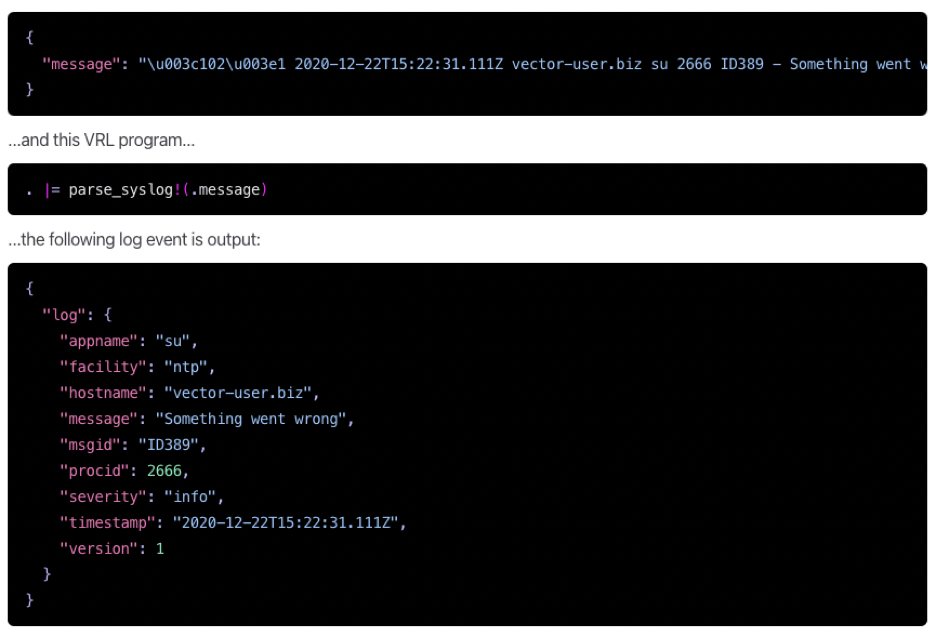
Once all of your VRL data transformation rules are added to a Vector config file, they will be applied to your observability pipeline.
Vector is great for: Datadog users! While Vector is vendor agnostic, Datadog has a product dedicated to simplifying and managing your Vector observability pipeline.
Cribl
Cribl is a company that specializes in observability data management to help reduce vendor lock-in and reduce the cost of observability, which also applies data transformation like log file parsing.
Cribl sits in between your data source and observability back-end to enrich and control the data that enters your observability analytics. As data enters the Cribl “pipeline”, the data is processed by a series of functions configured by the users. According to Cribl, data “processing” can mean string replacement, obfuscation, encryption, event-to-metrics conversions, etc.
Each function is written as an independent piece of JavaScript code that is invoked for each event that passes through them, which can be controlled by “filters,” another core component of Cribl’s architecture.
There are three functions that can parse your logs, including 1) grok, 2) regex extract, and 3) the parser function.
While Grok, as we discussed, is a rather unintuitive log parsing technology, grok patterns still remain one of the most popular ways to parse logs, so its unsurprising Crible offers it as a parsing option.
You can also use Regex extract to create fields that can be used by other functions downstream, but will NOT exit the pipeline.
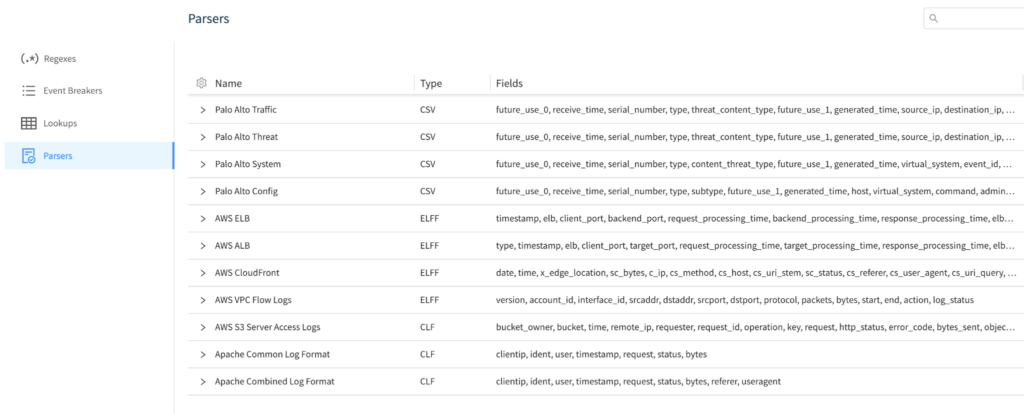
And finally, the parser function offers a more simple way to parse your data compared to grok. To get started with the parser function, you can go to the parser library (shown in the screenshot below from Cribl docs), where you can create and edit parsers.
At the most basic level, users can create a parser by filling out the wizard below (also from Crible docs).
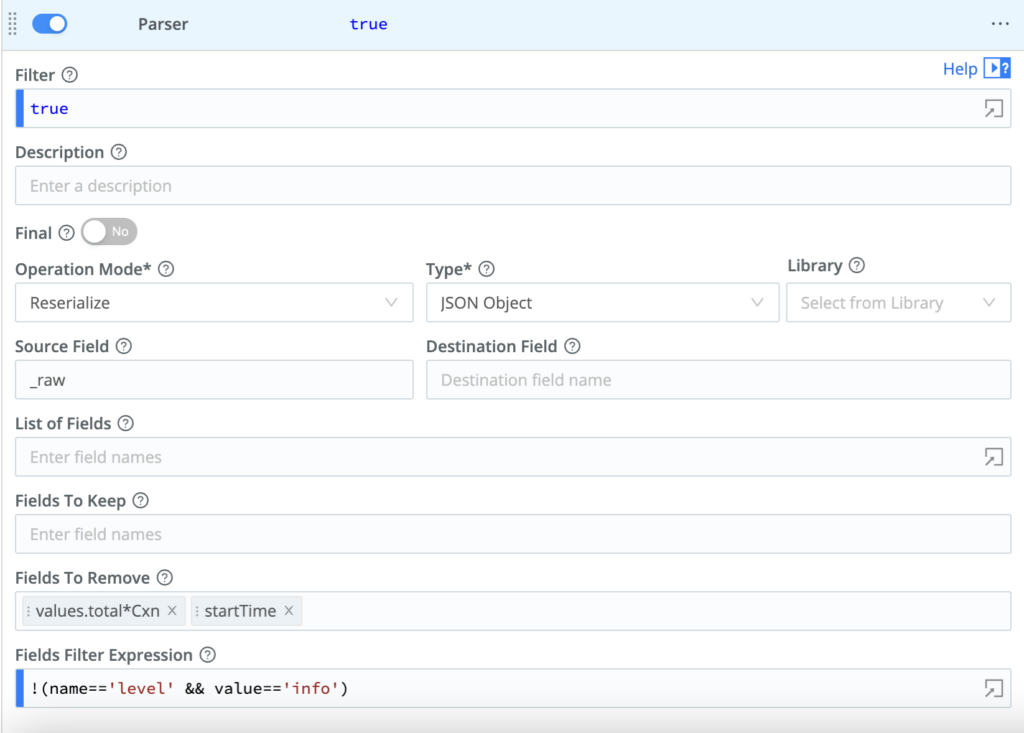
Here are brief explanations of some of the key components above:
- ‘Filter’ defines which data the parser will process
- ‘Final’ determines whether the data will move on in the pipeline, or not
- ‘Operation mode’ determines whether the function will create a new field or reserialize (overwrite) the fields
- A ‘source field’ defines the data the parser will extract, and the ‘destination field’ defines the field it will create
- List of fields: Field that are expected to be extracted, in order
Cribl is great for: large scale and/or advanced observability pipeline management. Cribl is feature-rich and focuses solely on observability pipelines.
Which log parser is best for you?
As mentioned toward the beginning of this article, the tools compared here are not standalone log parsers. Rather, they all have varying sets of capabilities that expand beyond log file parsing.
This is important to consider when you’re deciding on a log parsing technology, so that you’re not completely overwhelmed or underwhelmed with the feature set.
To summarize the comparison, here is how I’d recommend the technologies above:
- Use Logz.io for low-maintenance and low-cost log parsing, log analytics, and observability. Parsing is just a small part of what we do, and it doesn’t require any work from the customer (see parsing-as-a-service).
- Use Fluentd if you’re looking for a free log collector and parser. Fluentd is especially great for cloud-native environments running on Kubernetes.
- Use Logstash if you’re currently using it and don’t want to replace it.
- Use Vector if you’re a Datadog customer. Vector is vendor agnostic, but especially great for Datadog users because they have a product dedicated to maximizing Vector’s value.
- Use Cribl if you need large scale and/or advanced observability data pipeline management.
I hope this helps! Let me know if you have any other good log parsing tools in the comments.
You Might Also Like
Grok Pattern Examples for Log Parsing

