
Getting Started with Kibana Advanced Searches
August 20, 2018

Kibana is an extremely versatile analysis tool that allows you to perform a wide variety of search queries to find the data you’re interested in and build beautiful visualizations and dashboards on top of these queries.
In a previous article, we covered some basic querying types supported in Kibana, such as free-text searches, field-level searches and using operators. In some scenarios however, and with specific data sets, basic queries will not be enough. They might result in a disappointing “No results found” message or they might result in a huge dataset that is just as frustrating.
This is where additional query types come in handy.
While often defined as advanced, they are not difficult to master and often involve using a specific character and understanding the syntax. In this article, we’ll be describing some of these searches — wildcards, fuzzy searches, proximity searches, ranges, regex and boosting.
Wildcards
In some cases, you might not be sure how a term is spelled or you might be looking for documents containing variants of a specific term. In these cases, wildcards can come in handy because they allow you to catch a wider range of results.
There are two wildcard expressions you can use in Kibana – asterisk (*) and question mark (?). * matches any character sequence (including the empty one) and ? matches single characters.
For example, I am shipping AWS ELB access logs which contain a field called loadbalancer. A production instance is spelled incorrectly as ‘producation’ and searching for it directly would not return any results. Instead, I will use a wildcard query as follows:
type:elb AND loadbalancer:prod*
I could also use the ? to replace individual characters:
type:elb AND loadbalancer:prod?c?tion
Since these queries are performed across a large number of terms, they can be extremely slow. Never start your query with * or ? and try and be as specific as possible.
Fuzzy searches
Fuzzy queries searches for terms that are within a defined edit distance that you specify in the query. The default edit distance is 2, but an edit distance of 1 should be enough for catching most spelling mistakes. Similar to why you would use wildcards, fuzzy queries will help you out when you’re not sure what a specific term looks like.
Fuzzy queries in Kibana are used with a tilde (~) after which you specify the edit distance. In the same example above, we can use a fuzzy search to catch the spelling mistake made in our production ELB instance.
Again, without using fuzziness, the query below would come up short:
type:elb AND loadbalancer:productio
But using an edit distance of 2, we can bridge the gap and get some results:
type:elb AND loadbalancer:productio~2
Proximity searches
Whereas fuzzy queries allow us to specify an edit distance for characters in a word, proximity queries allow us to define an edit distance for words appearing in a different order in a specific phrase.
Proximity queries in Kibana are also executed with a tilde (~) following the words you are looking for in quotation marks. As with fuzzy queries, you define the edit distance after the ~.
For example, say you’re looking for a database error but are not sure what the exact message looks like. Using a free-text query will most likely come up empty or display a wide range of irrelevant results, and so a proximity search can come in handy in filtering down results:
"database error"~5
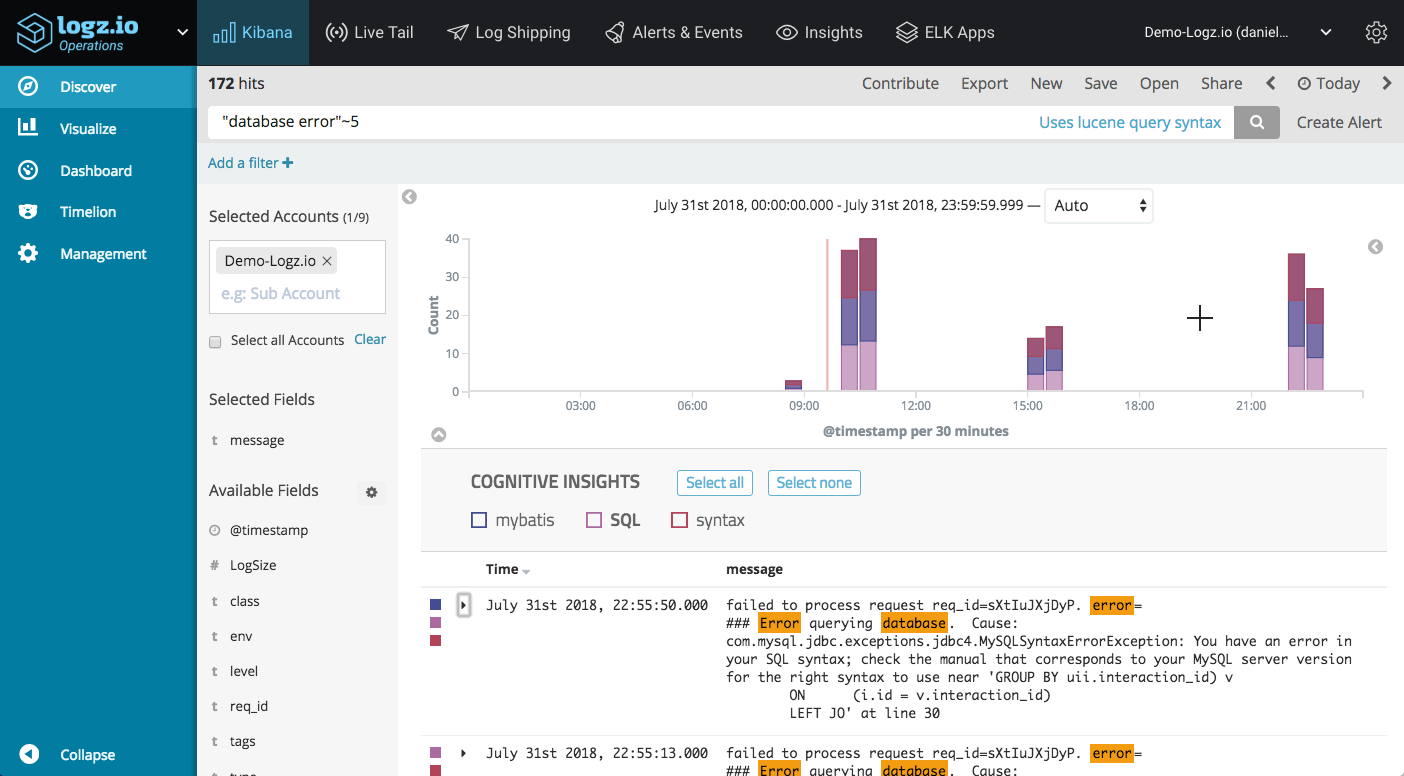
Boosting
Boosting in queries allows you to make specific search terms rank higher in importance compared to other terms.
To boost your queries in Kibana, use the ^ character. The default boost value is 1, where 0 and 1 reduce the importance, or weight, you want to apply to search results. You can play around with this value for better results.
error^2 database api^6
Regular expressions
If you’re comfortable with regular expressions, they can be quite an effective tool to use in queries. They can be used, for example, for partial and case-insensitive matching or searching for terms containing special characters.
To embed regular expressions in a Kibana query, you need to wrap them in forward-slashes (“/”).
In this example, I’m looking for IPs in the message field:
message:/[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}/
Below, I’m searching apache access logs for requests containing a specific search URL:
request:/\/search\/.*/
I recommend reading up on the syntax and the allowed characters in the documentation. Elasticsearch uses its own regex flavor that might be a bit different from what you are used to working with.
Keep in mind that queries that include regular expressions can take a while since they require a relatively large amount of processing by Elasticsearch. Depending on your query, there may be some effect on performance and so, if possible, try and use a long prefix before the actual regex begins to help narrow down the analyzed data set.
Ranges
Ranges are extremely useful for numeric fields. While you can search for a specific numeric value using a basic field-level search, usually you will want to look for a range of values.
Using Apache access logs again as an example, let’s say we want to look for a range of response error codes:
- response: [400 TO 500] – searches for all response errors ranging between code 400 and 500, with the specified values included in results.
- response : [400 TO 500}– searches for all response errors ranging between code 400 and 500, with 500 excluded from the results.
- response:[400 TO *]– searches for all response errors ranging from code 400 and above.
- response:>400 – searches for all response errors ranging from code 400 and above, excluding 400 from the results.
- response:<400 – searches for all response errors ranging from code 400 and below, excluding 400 from the results.
- response:>=400 searches for all response errors ranging from code 400 and above, including 400 in the results.
- response:<=400 searches for all response errors ranging from code 400 and below, including 400 in the results.
Bonus – non-existing fields
To wrap up this article, I thought I’d mention two methods to quickly look for documents that either contain a field or do not contain a field. This can be useful if you’re acquainted with the structure of your logs and want to narrow down results quickly to specific log types.
- _missing_ – searches for all documents that DO NOT contain a specific field, or that contain the field but with a null value.
- _exists_ – searches for all documents that DO contain a specific field with a non-null value.
As always with learning a new language — mastering Kibana advanced searches is a matter of trial and error and exploring the different ways you can slice and dice your data in Kibana with queries.
I’ll end this article with two tips. First, the better your logs are structured and parsed, the easier the searching will be. Second, before you start using advanced queries, I also recommend understanding how Elasticsearch indexes data and specifically — analyzers and tokenizers.
There are so many different ways of querying data in Kibana — if there is an additional query method you use and find useful, please feel free to share it in the comments below.
Happy querying!

You Might Also Like

Tool Consolidation Is Dead. Long Live Agentic AI.

