Cracking Performance Issues in Microservices with Distributed Tracing
October 25, 2022

Microservices architecture is the new norm for building products these days. An application made up of hundreds of independent services enables teams to work independently and accelerate development. However, such highly distributed applications are also harder to monitor.
When hundreds of services are traversed to satisfy a single request, it becomes difficult to investigate system issues. This includes when a customer request returns a failure code, or if a customer request is suddenly very slow to respond.
While logs have been an established tool for analyzing root causes, microservices architecture is not monolithic. There can be hundreds or thousands of services involved, each making thousands of requests per second.
With log entries then scattered across numerous log files, how can you determine which are relevant to the request at hand, or put them together according to the execution flow?
Distributed Tracing Fundamentals
This has given rise to the new discipline of Distributed Tracing. Google released a monumental research paper in 2010 following their experience building Dapper, their own in-house Distributed Tracing system. According to OpenTracing.org:
“Distributed tracing, also called distributed request tracing, is a method used to profile and monitor applications, especially those built using a microservices architecture. Distributed tracing helps pinpoint where failures occur and what causes poor performance.”
In essence, Distributed Tracing helps us:
- Pinpoint the sources for request latency
- Identify the critical path in our requests
- Find the service at fault when experiencing an error
- Understand the service dependency graph
- Realize the full context of the request execution
How is Distributed Tracing data gathered? It all starts with instrumenting our application, similarly to the way we instrument for logs or metrics. Once instrumented, our application reports tracing data for each service and operation that is invoked as part of the request execution. This data, called spans, is typically collected by a collector or an agent, where it is ordered by causality, processed, and then sent to the analytics backend for storage and visualization, typically as a Gantt chart.
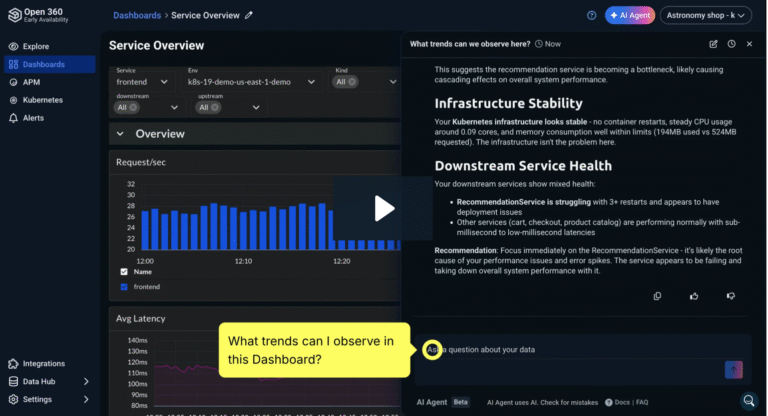
In the example below, we can see a trace, starting with the HTTP GET /dispatch operation invoked on the frontend service and then flowing through a series of services and operations to fulfill.

In this example, it’s easy to see where most of the time is spent and potential performance inefficiencies, such as a series of sequential calls that, if run concurrently, could reduce the overall request latency.
If you want to see this example investigation in action over a live demo along with more investigation steps, check out my talk at WTF is SRE 2023 conference in London:
Distributed Tracing is Growing in Popularity
Distributed tracing has been growing in popularity in recent years. According to the DevOps Pulse 2022 survey, 47% use distributed tracing in one form or another. In fact, distributed tracing adoption has seen a steady increase throughout the last three years, per DevOps Pulse’s yearly results.
Moreover, among those who do not yet use it, 70% of the 2022 survey respondents stated they intend to start using it in the coming one or two years.
Open Source Plays a Key Role in Distributed Tracing
Open source plays an important role in this domain. The most popular distributed tracing tool is Jaeger Tracing. According to DevOps Pulse, Jaeger is used by over 32% of distributed tracing practitioners. Jaeger was developed by Uber for its own hyperscale needs and was later open-sourced.
Today, Jaeger is a graduate project in the Cloud Native Computing Foundation (CNCF), the organization that hosts Kubernetes, Prometheus and other prominent cloud-native open-source projects.
Another important open source project in this space is OpenTelemetry, which is used for generating and collecting the tracing data, alongside metrics and logs, in a unified and standard manner.
OpenTelemetry provides API and SDK for instrumenting applications in various programming languages, as well as a Collector for collecting the telemetry data from applications and from infrastructure components. OpenTelemetry is also a CNCF project; it has reached general availability for Distributed Tracing in 2021 and is considered ready for production use.
How SLOs Impact Distributed Tracing Effectiveness
A microservice architecture is a mesh of services that must work well together to function. In these systems, tens and even hundreds of services may be traversed to satisfy a single user request. In these cases, rather than monitoring individual services, SLI and SLO should be defined for flows and user journeys.
[Note: A Service Level Indicator (SLI) is a carefully-defined quantitative measure of some aspect of the level of service that is provided, such as latency, error rate, request throughput and availability. A Service Level Objective (SLO) is a target value or range of values for a service level that is measured by an SLI. For example, an SLO can state that the average latency per request should be under 120 milliseconds.]
The complex request flows brought about the rise of distributed tracing as a discipline. It’s typically used to pinpoint where failures occur and what causes poor performance. However, tracing can also be used to trace FinOps and business workflows.
Google Dapper is in fact one of the forefathers of modern distributed tracing, which served as inspiration for tools such as Jaeger and Zipkin. According to Ramón Medrano Llamas, a staff site reliability engineer at Google who leads the SRE team in charge of Google’s identity services: “it’s the closest tool we have right now for a definite observability tool.”
To make things more interesting, these user journeys not only span several services, but may actually involve a few requests.
Here’s an example with the Google sign-in process: as Llamas shares, what used to be a matter of three calls in the pre-microservices era today is a full business flow, consisting of multiple steps: loading page, then inputting username and password, then 2FA, and so on.
Each individual step is a request, triggering a chain of microservices to satisfy. The overall multi-step flow isn’t stateful; it depends on the end user to carry it over from step to step. Monitoring these business flows is less trivial, but that’s what must be measured to ensure the functionality delivered to the user.
Tracing definitely stands out as a central tool for monitoring microservices and distributed systems, and augmenting logs and metrics. To learn more about this topic watch my talk at WTF is SRE 2023 conference.
Microservices architecture can be hard to grasp at scale. With the right tools, you can gain a system-wide view to:
- Trace the call sequence through your system from any service endpoint
- Auto-discover and visualize your service map
- Optimize the performance and latency path of your distributed requests and transactions
If you’re looking to take your distributed tracing practice to the next level, try it out yourself for free, or feel free to schedule a Logz.io demo here.

You Might Also Like

What’s New at Logz.io – January 2026

