
Automate Observability Tasks with Logz.io Machine Learning
December 15, 2022

As an observability provider, we are always confronted with our clients’ goal for faster resolution of problems and better overall performance of their systems. By working on large-scale projects at Logz.io, I see the same main challenge coming up for all: extracting valuable insights from huge volumes of data generated by modern systems and applications. With traditional methods, it can be difficult for DevOps teams to control costs and manually analyze and interpret this data in a timely manner.
Our data science team has put in an incredible amount of work to enable DevOps teams to automate this process. The process quickly identifies anomalies that may require attention, reducing MTTD/MTTR.
This blog will highlight the work of our team. We’ll dive into:
- A summary of Logz.io’s anomaly detection algorithms
- How to predict and alert on data shipping bursts using Logz.io’s AI
- Logz.io’s other ML-based patented technologies
The investments we’ve made in Machine Learning are aimed at helping our customers automate common observability tasks to achieve goals including:
- Automatic anomaly detection to reduce service interruptions
- Accelerate debugging and troubleshooting to reduce service interruptions
- Identify anomalous data spikes to reduce costs
1. Anomaly Detection Algorithms
ML-based anomaly detection typically involves training a machine learning model on a large dataset of normal behavior for a given system. This model can then be used to automatically detect deviations from the normal behavior, which may indicate the presence of an anomaly.
Depending on the specific application, the machine learning model may be trained to detect a wide range of different anomalies, from simple patterns to more complex and subtle behavior. By using a unique ensemble of unsupervised learning models, DevOps teams can improve the accuracy and effectiveness of their anomaly detection systems.

Logz.io uses several algorithms for prediction and anomaly detection; the algorithms are chosen automatically according to which part of the system is being monitored.
For instance, anomaly detection for data without categorical fields (e.g.: IP address, country, user name, etc.) will be classified differently than for data with many categorical fields.
Numerical data-based algorithms: Predicted Vs. Actual detection
***Heavily used internally for Logz.io’s production environments, to be released soon***
Logz.io uses a set of boosting-based algorithms, whose primary function is to reduce bias by converting weak learners to strong learners. This way, Logz.io forecasts and predicts metric data and uses time-series analysis to perfectly fit the algorithms to the working days/hours pattern.
Logz.io uses boosting-based algorithms to forecast/predict metric data and uses time-series analysis to perfectly fit the algorithms to the working days/hours pattern.
Logz.io’s system constantly learns the metric and trace data patterns, and predicts in real-time what should have happened compared to what actually happened.
How does it actually work?
Logz.io’s algorithms are learning the behavior of trace and metric data for the last 3 months (the time frame can be modified per account, and the learning does not require hot retention for the same period of time).
Based on the model elaborated during the learning, which is updated with high frequency, we can determine in real-time if there is a high difference between predicted and actual values, representing an anomaly.
In the image below, you can see the mechanism applied:
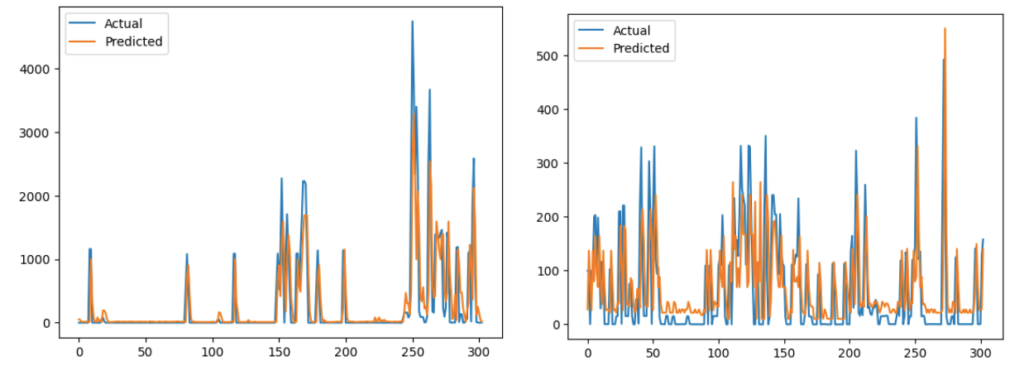
The first graph compares the prediction of metrics and tracing data volumes vs. the actual data volumes, while the second graph shows the difference between predicted and actual volumes.Rule applied: An anomaly is detected if the difference between predicted and actual metrics and trace volumes shipped is greater than a specific threshold (e.g., 2.0).
Numerical & Categorical value algorithms
For categorical data, Logz.io uses a patent-pending technology to embed various isolation-forest algorithms that outperform the OpenSearch built-in anomaly detection. Logz.io is always monitoring and testing several algorithms to improve the anomaly detection accuracy.
APM anomalous detection
***Currently in Alpha version internally for Logz.io’s platform monitoring. To be released in 2023 for closed-beta customers.***
Logz.io’s APM monitors trace data of each service, predicting and detecting the following abnormal use-cases per each service:
- Request rate (throughput)
- Latency
- Error rate
For instance, in the image below, you can see how Logz.io forecasts and learns each of these use cases for each of the customers’ services.

Anomaly Detection Task Management
Logz.io provides an anomaly detector for any service/parts of the system. Our platform allows you to define, from the admin panel, specific anomaly detectors for any service or data source.
In the example below, Logz.io defined two anomaly detectors to detect two logging anomalies from two parts of the system: OneLogin data & ActiveDirectory data.
Each anomaly detector is defined with the following Lucene-based query:
type:onelogin AND _exists_:@timestamp.

Within the anomaly detection task, we can define the fields’ combinations that would be taken into account to detect the anomaly and other parameters based on which anomalies are detected. Examples of such a parameter would be:
- The period in minutes between each detection (the window size is 15 minutes in the example above)
- Threshold 0-1 for the severity of events

By running the query type:onelogin AND _exists_:@timestamp, we can define an anomaly detector for specific field combinations and can have alerts based on those fields.

2. Predicting and alerting on data shipping bursts: Anomaly Detection & Forecast on Ingestion ValidLogBytes
General built-in anomalous shipping burst detection
For any account/sub-account, log, metric, and trace data volumes are converted into an internal shipping metric: ValidLogBytes (number of log bytes) ingested. Logz.io monitors this shipping metric and uses anomaly detection to predict and detect anomalies per specific account.
Logz.io’s users can define to which sub-accounts the anomaly detection indications are sent. Typically, users create dedicated sub-accounts for ML indications to define alerts accordingly.
It marks with red annotations data shipping anomalies and provides a score for each anomaly, representing its severity level.

The problem – anomalous data spikes drive up costs: It is difficult to act quickly enough to proactively reduce data volumes as costs are spiking.
The solution – Predicting and alerting on data shipping bursts: Using Numerical data-based algorithms, Logz.io compares predicted vs. actual data volumes to identify and alert on anomalous cost spikes.
The result – lower observability costs: When teams are equipped with the tools to identify and take action on costly data volume spikes, they can reduce costs.
For each anomaly detected, Logz.io generates a log entry describing the abnormal event, and the user can define alerts based on the event and its severity score.
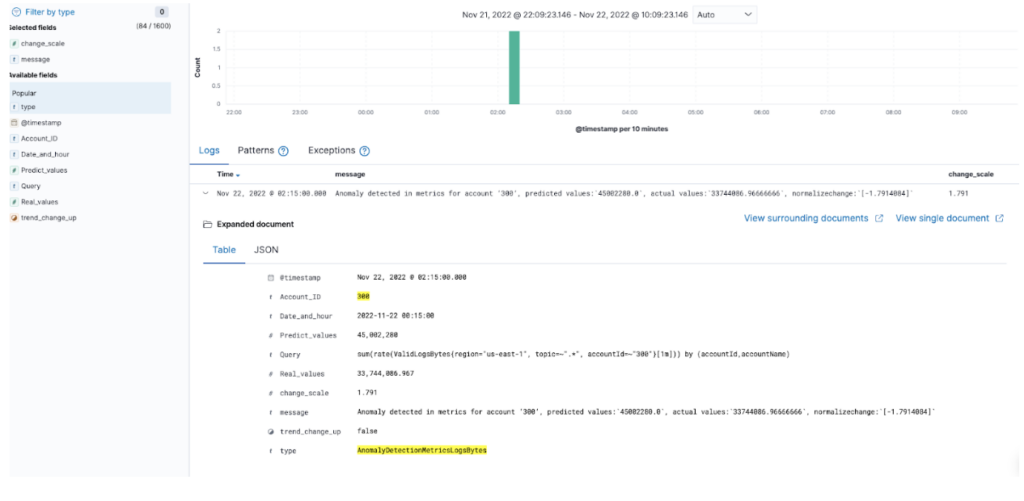
Below you can find an example of Logz.io’s own telemetry volumes anomaly detection by forecast – considering (1)seasonality and (2)volumes calculated in real-time.


Metric and Trace data shipping burst – Predicted Vs. Actual
Using Numerical data-based algorithms, Logz.io can determine in real-time if there are anomalous metric and trace data volumes shipped based on the model elaborated during the learning.
3. Cognitive Insights: AI-based data enrichment.
Logz.io has an approved patent for its cognitive insights technology. It combines machine learning and crowdsourcing to automatically uncover critical issues in log data – which could otherwise easily go unnoticed in large data volumes – with actionable remediation information.
How does it work?
For example, one of Logz.io’s customers gets an error 750 – timeout expired, from MongoDB. Since MongoDB generates thousands of log types, how can they know if that log event is important? Logz.io will therefore match that log against what other developers around the world think of it.

In fact, Logz.io ongoingly scrapes the Internet for texts from dev repositories (Github, StackOverflow, etc.) and isolates issues that have been documented there. If any of those issues matches the customer’s incoming logs, it is automatically flagged with a link to the remediation documentation.
Logz.io has a dedicated cognitive insights screen (navigation from Logz.io), as presented in the images below:

Logz.io Machine Learning in Summary
Overall, Logz.io uses machine learning algorithms to detect anomalies in system behavior automatically. These algorithms are trained on large datasets of normal behavior and can detect a wide range of different anomalies.
Logz.io’s technology is constantly learning and updating its predictions in real-time and can be used to predict and alert on anomalies, critical troubleshooting data, and expensive data shipping bursts. These tools help DevOps teams reduce costs and quickly identify and resolve issues – leading to better performance and faster problem resolution.

You Might Also Like

A List of the Best Open Source Threat Intelligence Feeds

