
Introducing the VictorOps Integration in Logz.io
January 23, 2018

We are happy to announce a new integration with one of the popular incident management platforms currently in the market – VictorOps!
Logz.io supports hooking up the alerting engine with any application that accepts data via REST API. Meaning, that to send off a log-based alert, all that is needed is a webhook URL and any additional parameters required by the API.
However, Logz.io also supports a number of built-in integrations that make the process of triggering and sending off an alert a seamless process, including integrations with Slack, PagerDuty, Datadog, and BigPanda, and we have now added VictorOps to this list.
Let’s see how to use this integration.
Preparations in VictorOps
As an initial step, we first need to retrieve some details from VictorOps to enable the integration — a REST API key, and a Route Key.
Retrieving your REST API Key
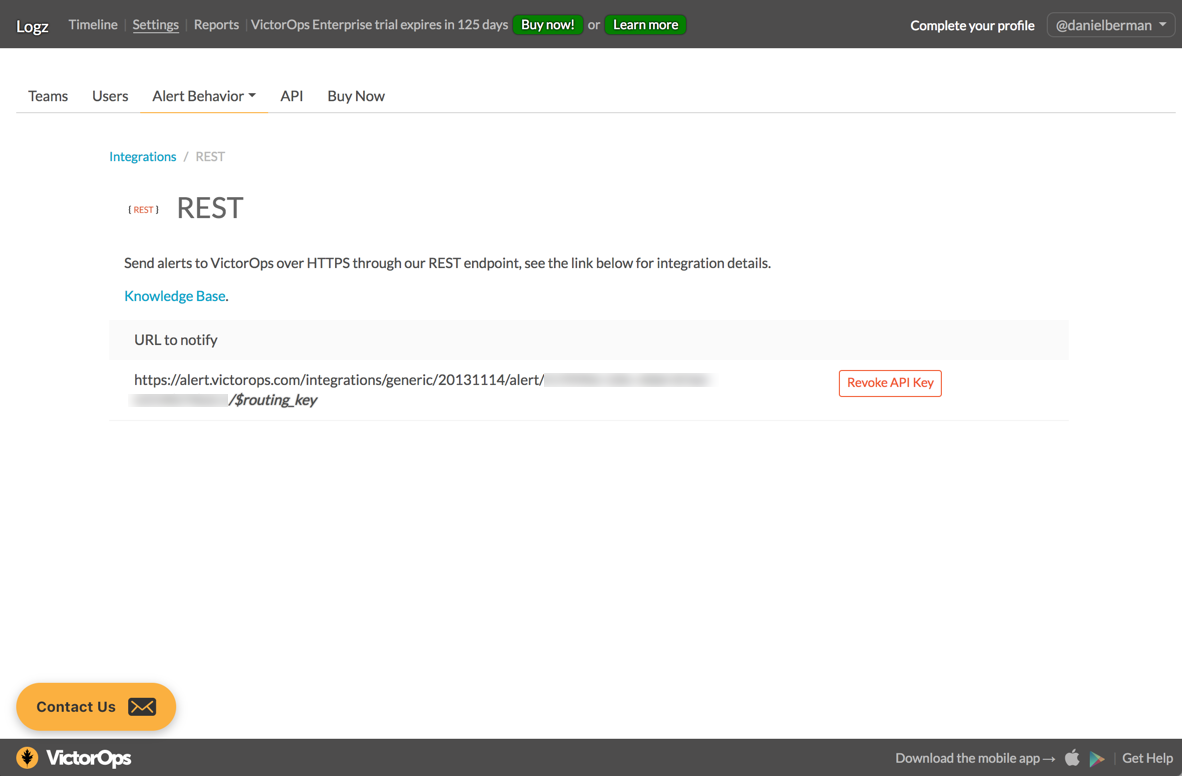
To retrieve the REST API key, go to the Settings page in VictorOps, and then select Integrations from the Alert Behavior menu.

From the list of integrations, select the REST Generic integration. You will then see the <API key> within the URL:
https://alert.victorops.com/integrations/generic/20131114/alert/ <API key>/$routing_key
Retrieving your Routing Key
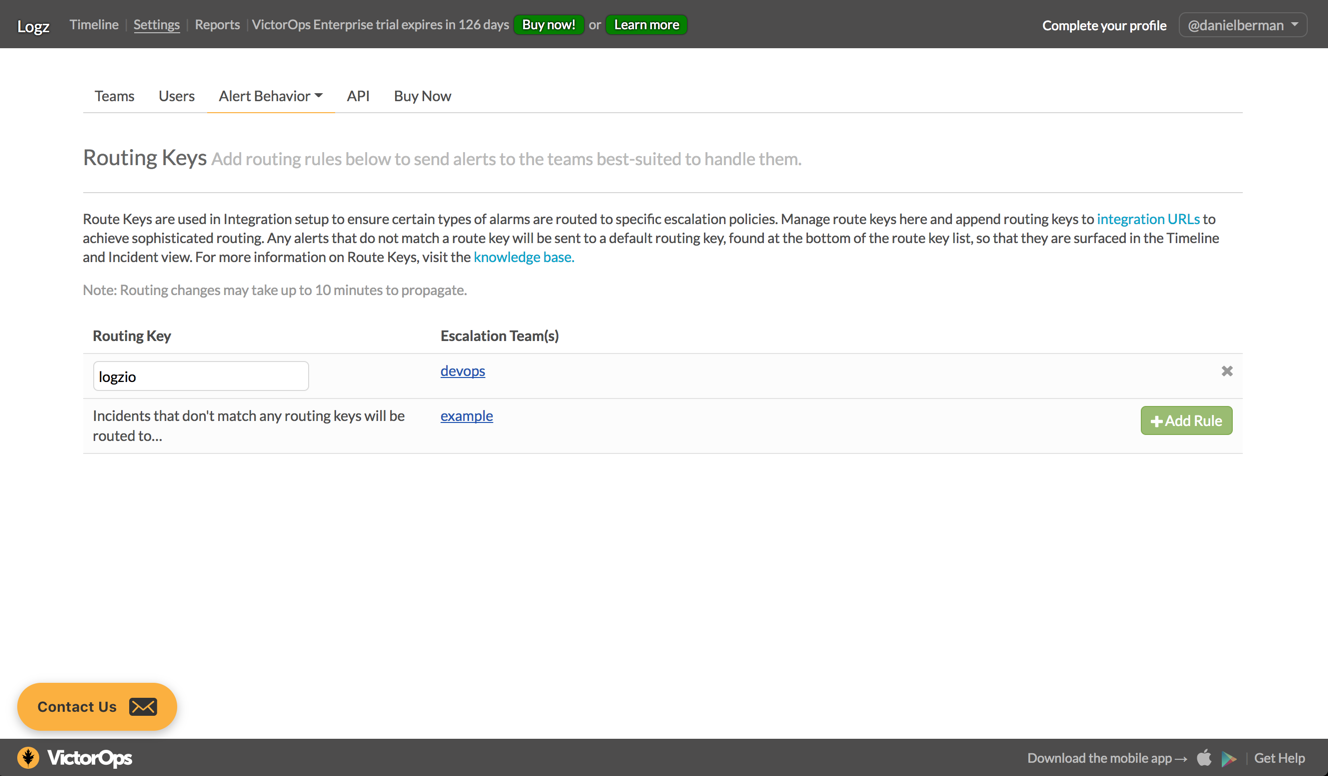
As their name implies, Routing Keys in VictorOps allow you to assign specific types of alerts to specific groups in your organizations, the idea being that only those belonging to a specific team get notified.
You will need to create a Routing Key and then associate them with a specific team. This is done on the Settings page as well. Go to Alert Behavior → Route Keys. In the example here I created a new Route Key called ‘logzio’ and associated it with my ‘DevOps’ team.
Creating your VictorOps endpoint
Now that we have all the required ingredients for setting up the integration, we can now create our new VictorOps endpoint in Logz.io.
In Logz.io, go to the Alerts → Alert Endpoints page and click Create a New Endpoint.
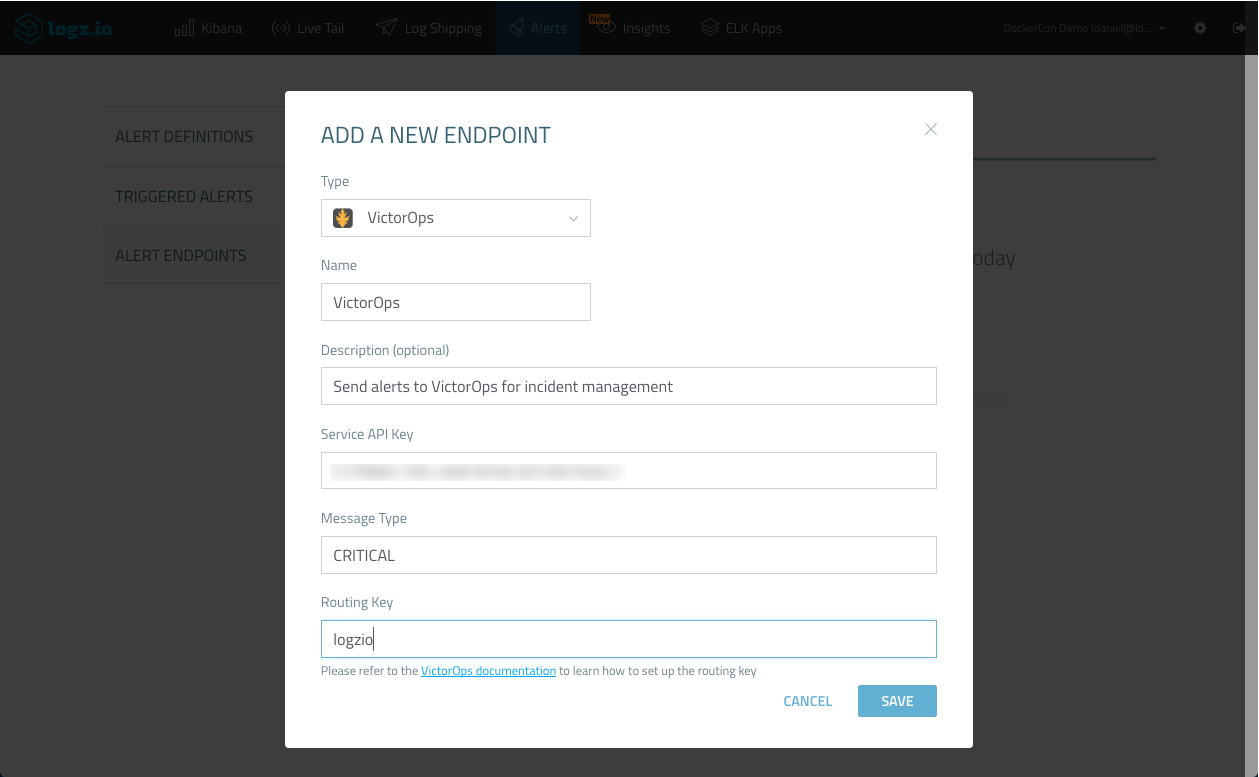
Under Type, select the VictorOps endpoint, and enter the following details:
- Name – enter a name for the endpoint (e.g. VictorOps)
- Description (optional) – describe your endpoint
- Service API Key – your VictorOps REST API key
- Message Type – this determines how VIctorOps handles the alert. To create an incident, for example, enter ‘CRITICAL’. You can read about the other options for this variable here.
- Routing Key – your VictorOps Routing Key
Hit Save, and your new endpoint can now be used for creating an alert.
Creating an alert
In this case, I’m using the Docker Log Collector to monitor my Dockerized environment. As a reminder, the log collector is a lightweight container that ships Docker container logs, Docker stats and Docker daemon events into Logz.io.
What I’d like to do, is get notified should container memory usage exceed the average metric.
To do this, I will first enter a Kibana query that queries docker-stats:
type:docker-stats
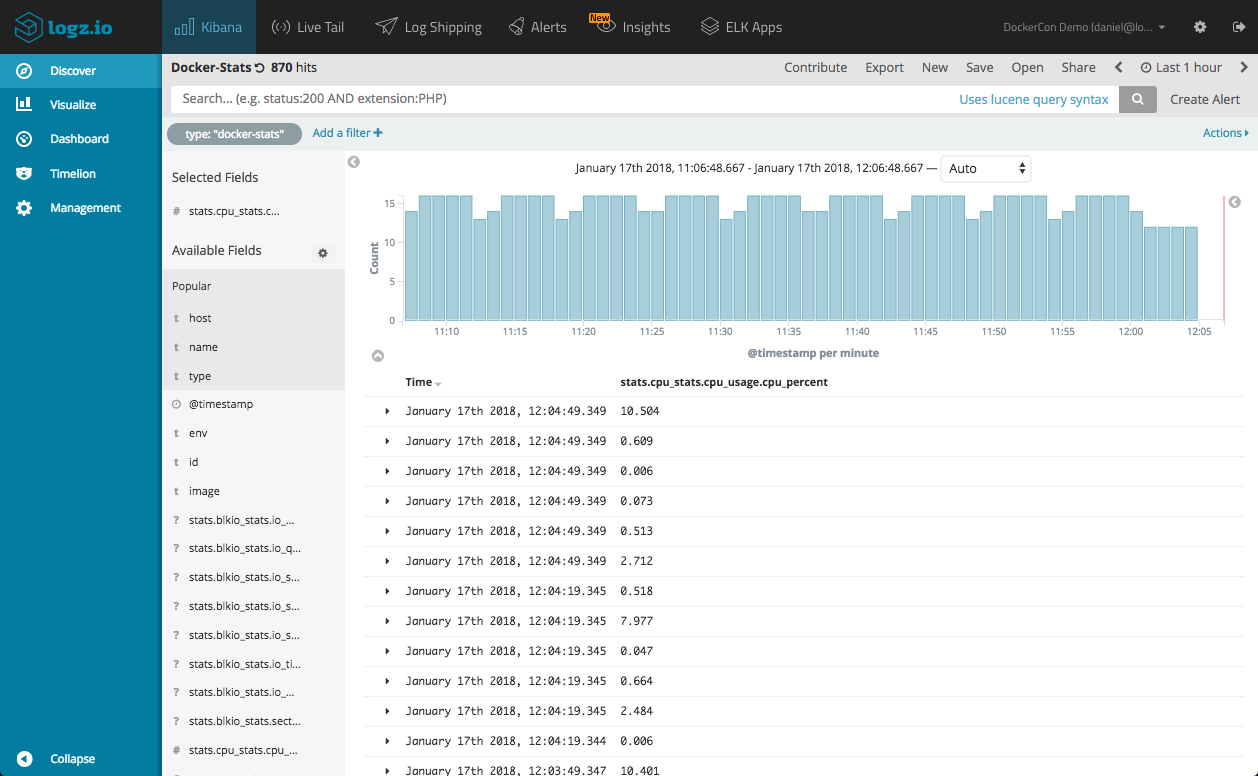
Note: to discover the normal value, I recommend creating a metric visualization.
Next, I will click the Create Alert button to begin defining the alert.
The query we used is already defined, so we will commence with defining the trigger, asking the Logz.io alert engine to send off an alert should average memory exceed 300MB.
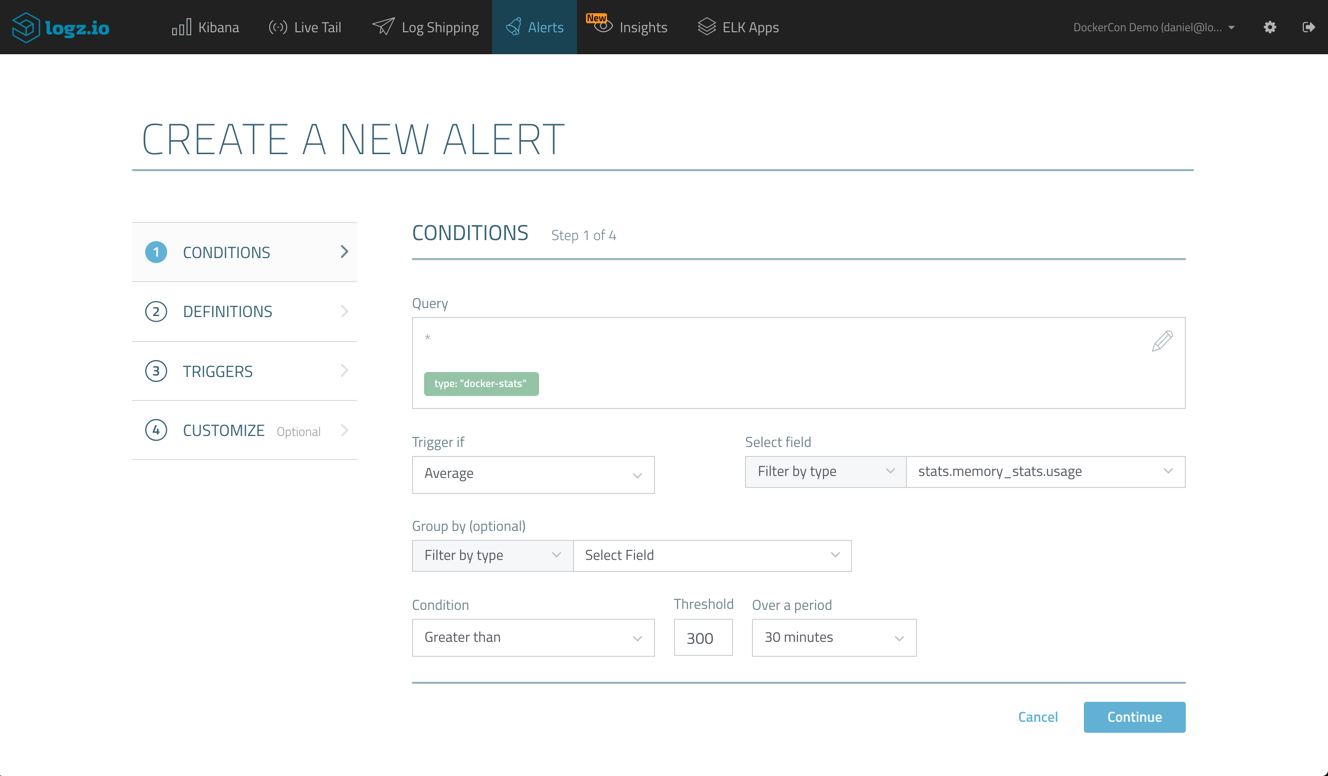
In the next steps of the wizard, I will enter a name and description for the alert, and define the VictorOps endpoint we created before as the recipient for the alert.
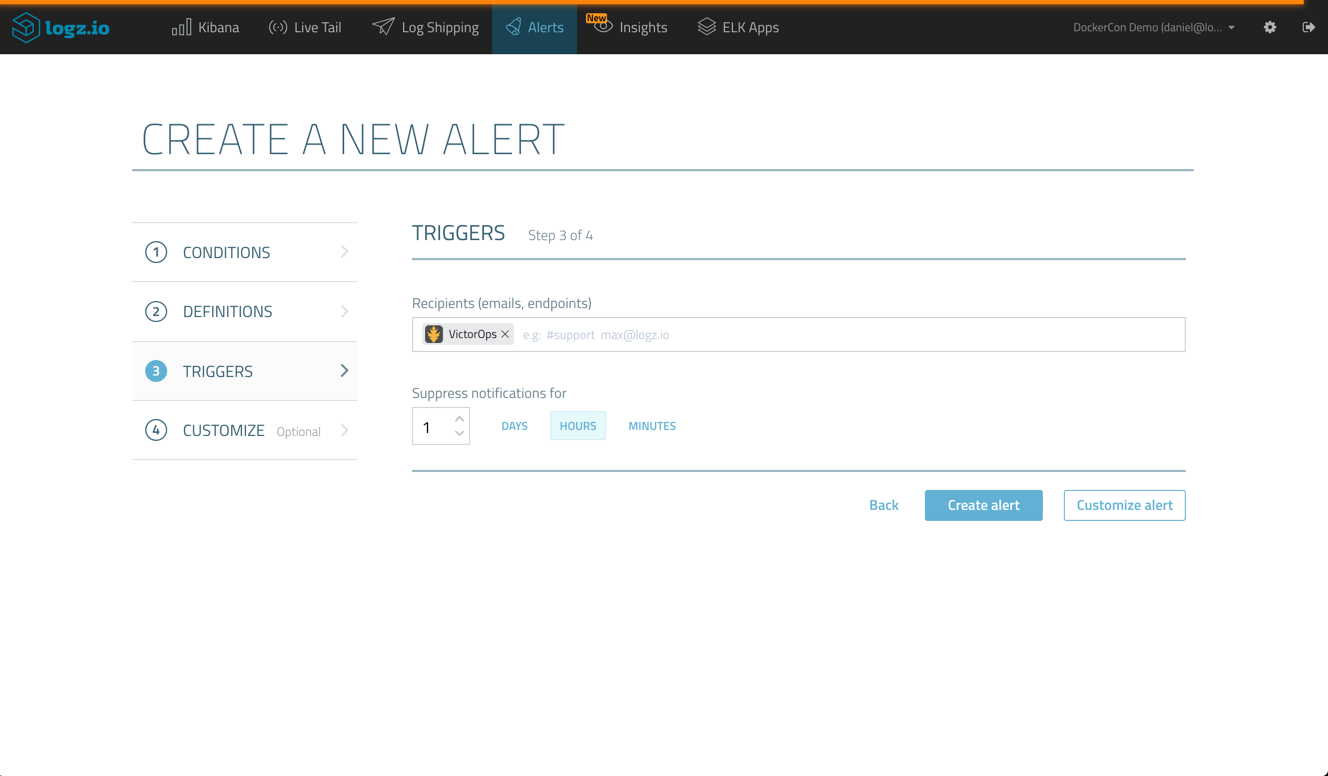
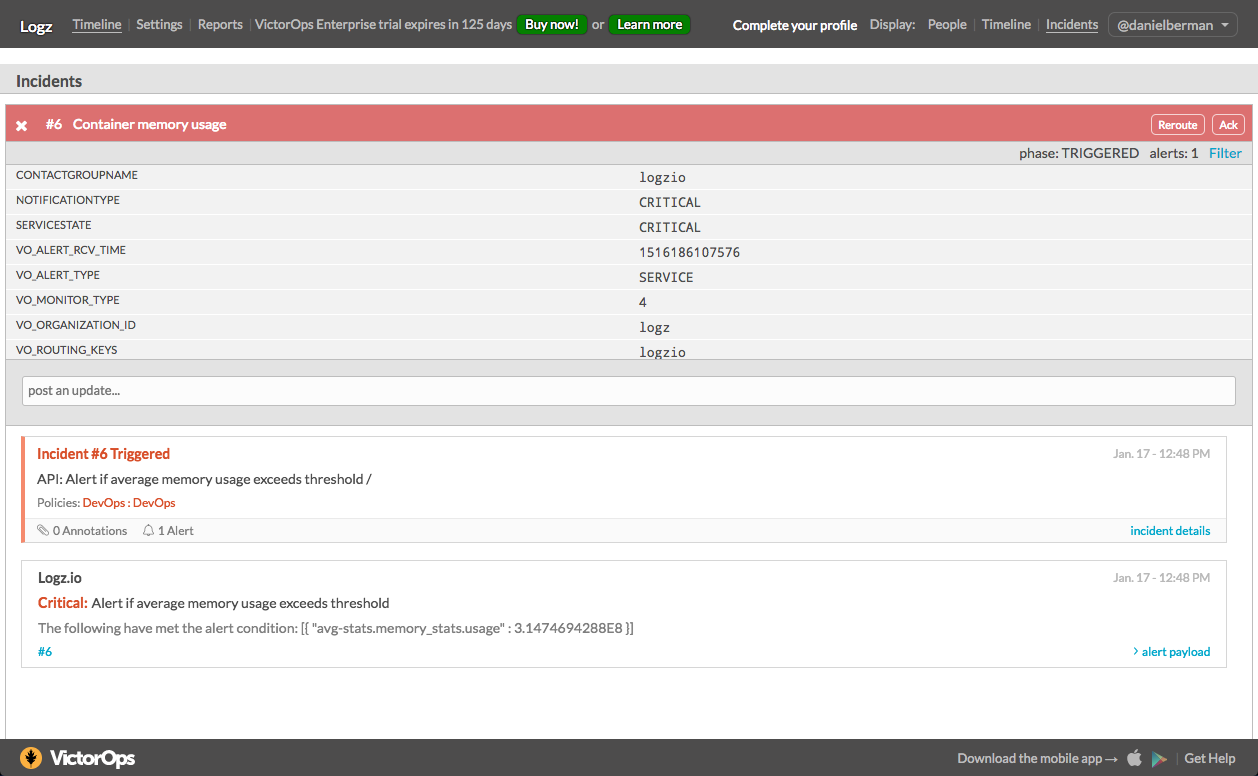
Once created, and according to our definitions, the Logz.io alert engine will begin to check whether the conditions for triggering an alert are met. If triggered, the alert will be sent to VictorOps and an incident opened. You will be able to see these in your timeline.
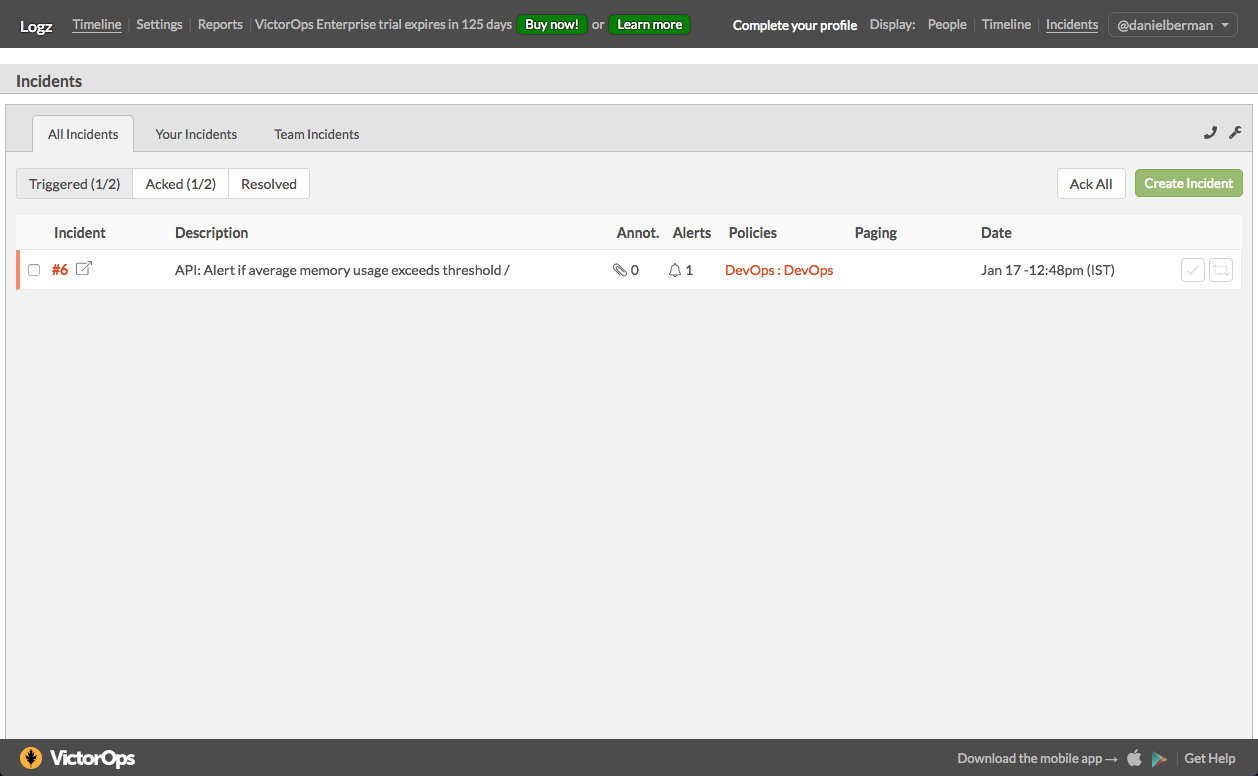
Opening the incident, you will be able to see additional details. In our case, we can see that the alert was triggered since an average aggregation for the ‘stats.memory._stats.usage’ metric exceeded our threshold.
Summing it up
Getting notified in real-time when a critical event is taking place is key to effective and successful operations. The challenge is, of course, alert fatigue. Organizations must make sure that, a) alerts are meaningful and actionable, otherwise they simply add to the general operational noise, and b) your organization knows how to handle them.More on the subject:
Log-based events and aggregations are probably one of the most accurate sources for triggering alerts, and combining a powerful alerting engine built on top of the ELK Stack together with an incident management platform such as VictorOps helps tackle these two challenges and fight the alert fatigue.

You Might Also Like

Calling All Observability All-Stars!

