
The Top 5 Incident Management Systems for DevOps
July 6, 2017

In his article “There’s No Such Thing As A Bug-Free App,” Rahul Varshneya, founder of Arkenea and the Appreneurship Academy, describes how NASA develops and handles its software. Yet, despite the hundreds of people planning, writing, and, most importantly, testing NASA’s code, defects still occur in software responsible for the lives of its astronauts. The goal of R&D is to develop software of the highest quality with minimal errors.
Meanwhile, the goal of DevOps is to ensure that every defect that is detected in production is addressed and prioritized according to its effect on the functionality or usability of the software. These production problems, which are handled by DevOps, are called “incidents.”
In 1998, NASA launched the Mars Climate Orbiter as part of the Mars Polar Lander program. About a year later, on September 23, 1999, the Orbiter stopped transmitting and was considered lost. A group of technicians spent more than twenty-four hours trying to operate a set of Deep Space Network antennas in a fruitless attempt to regain contact with the spacecraft. Think about trying to resolve a problem with software, while not knowing exactly where the software is located, only that it is a few million miles away.
Would NASA be able to tweet something like this?

Though ops teams used to follow ITIL principles, more modern approaches view these principles as obsolete and more applicable to waterfall life-cycles. As software release times shorten and the standard SLA for downtime or defect resolution nears zero, DevOps and incident management procedures must adjust accordingly. Incidents must be categorized and prioritized rapidly, preferably by an automatic service, then assigned and handled in collaboration with the relevant development and QA owners, in some cases pushing to supply a fix on the same day.
Customer-facing DevOps staff must have 24-hour, cross-time-zone coverage. Every SLA breach should trigger escalations and swift involvement of higher and more technical tiers. In order to keep applications running at all times, to handle incidents correctly, and to meet organizational standards, the right incident management tools are required. There are quite a few tools that can facilitate the process of attending to production incidents — the following are the top five.
![]()
PagerDuty is a system that automates the incident-handling process, so time and effort invested in production maintenance are reduced to a minimum. The tool collates alerts and events from all systems in the software environment and groups them based on contextual insights. It reduces the noise caused by multiple alerts for the same issue and helps to put the focus on the actual incident to improve resolution time. PagerDuty allows users to customize alerts and to capture and deliver the required information to the relevant person for every type of issue.
But the magic word here is “intelligence.” The tool gathers information and reads patterns from its incident database, helping to automate the escalation process and base its decisions on its experience with previous incidents in specific areas of the application. DevOps managers are provided with live views of all incidents and their statuses. As part of this real-time dashboard, incidents can be related, and the manager can decide to drill down and make decisions on incident lifecycle and routing.
The analytics and reporting provided by the tool help to track system performance trends and analyze the root causes of incidents. It also monitors the productivity of different teams, so the incident-handling lifecycle can be optimized for future events. PagerDuty recently introduced a mobile app, allowing users to stay connected and to manage and observe production incidents anytime and anywhere. PagerDuty also has more than 150 integrations for monitoring, deployment, and ticketing tools, so it’s easy to implement in the heart of the system and start seeing results immediately.

OpsGenie is a cloud-based application that puts alerting and communication at the center of incident management. Routing, notification rules, and mobile efficiency are the pillars on which OpsGenie is built. The first step in using the tool is to define on-call schedules for alert and notification routing. This application can handle geographically distributed teams and after-hours incidents and is capable of initiating appropriate response actions. OpsGenie provides a phone call service to follow up on non-addressed alerts. This is part of a broad escalation management service allowing different tiers and management levels to be notified of incidents, according to predefined rules based on incident severity and volume. All actions and decisions can be made from the OpsGenie mobile app, keeping everyone connected and responsive.
The lifecycle and notification list is thoroughly documented for each alert and is a feature that can be used for postmortems so that ops teams can detect any problems in the process and improve efficiency. From the point of view of ease of maintenance, organizations using this tool can consolidate notification management into a single space in which users can update their contact details and preferences, thus preventing data duplication and reducing administrative burden.

VictorOps describes itself as the alternative to PagerDuty. It’s a real-time platform for reacting to open incidents and preparing for future ones. Incident alerts are sent according to an on-call plan, but can also be redirected dynamically. The alerts are configurable “on the fly,” meaning that they can be altered to contain links to server logs or explanations of solutions that can be followed by anyone. Utilizing its integrations with other tools, VictorOps builds a “timeline” displaying every piece of information from the entire ecosystem, so incidents can be easily investigated and tied to other events.
VictorOps has also introduced the “transmogrifier,” a tool that allows everything — from alerts to incident flows — to be customized, making it simple to implement incident management in the way that best suits a given DevOps team. The tool also has a built-in chat function, which helps make collaboration even simpler so that the team can address problems faster and help each other find a solution.

Jira Service Desk is just one part of the complete Jira portfolio, helping development and DevOps to code, build, and ship their software in the best ways. Service Desk sees service providing as the most time-consuming activity. Therefore, the tool supplies a self-service module containing a knowledge base of helpful information so that users can help themselves before asking for assistance from customer service agents. The tool can be applied in both ITIL-driven organizations and those using newer incident management methodologies through its integrated problem and change management modules and produces a detailed workflow for each type of event in production.
Jira also provides numerous APIs, allowing simple integration with any CRM or ticketing management system already in place. This means that the organization can start using Service Desk quickly and without ramp up. Service Desk has an enterprise edition—Service Desk Data Center—allowing DevOps to focus on mission-critical services and disaster recovery plans.

FreshService is one-stop ITIL software that has solutions for the whole IT operations department. Its Incident Management module communicates with different channels to capture and report new incidents using a phone, chat, and even email. Each incident is prioritized, and—provided the relevant rules are in place—can be automatically routed to the right agent or team. From this point on, the incident information is stored and either analyzed for a quick solution or used to create a “problem” or even a “change.” Once resolved, the incident information is stored in the knowledge base as a suggestion for future similar incidents. The tool has the ability to automatically escalate incidents to different teams, based on response time.
FreshService has also created a survey module, allowing users and customers to supply feedback on the speed and efficiency of the resolution process, so teams can identify their stumbling blocks and improve in these specific areas. FreshService understands how major incidents affect organizations differently. Based on this understanding, a dedicated module, addressing only major incidents, was introduced. This module has separate processes, metadata, escalation methods, and higher management-involvement interfaces. Having this dedicated module allows incidents affecting a wide cross-section of customers to be dealt with faster and more efficiently.
Conclusion
Meeting incident SLAs and responding correctly and in a timely manner to production events are complex goals that require deep knowledge of the software’s front and back ends, high end-service orientation, and the right tools. The tools discussed in this article can serve as the infrastructure for incident-handling processes and as day-to-day support for the stakeholders while driving efficiency and improvement.
More on the subject:
Just as there is no perfect application, there is no perfect incident management software. This discussion has provided an overview of how each of the leading incident management tools attends to production service outages and attempts to implement solutions. Organizations first need to decide on their standards and service goals before choosing a tool with the appropriate features and focus.
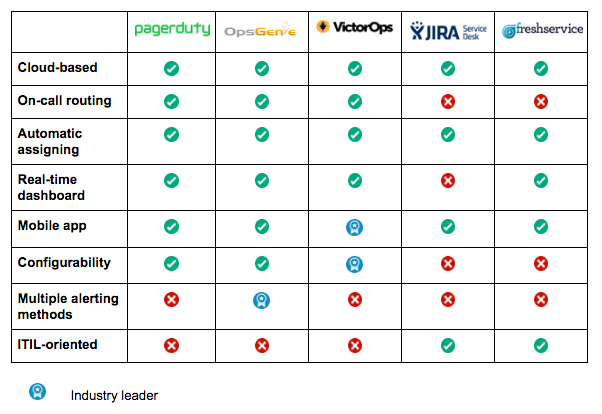
To summarize the difference between these incident management platforms, we have created the following chart based information collated from major research firms:

You Might Also Like

How Endeavor Streaming Accelerates Observability with Logz.io

