
Building Monitors you can Trust
April 23, 2018

When setting up monitoring systems, it’s incredibly easy to fall into the “more is better” trap: you don’t know what your monitoring system can’t tell you. Unfortunately, as production systems grow and increase in complexity, even at small companies, the “noise” level can become increasingly unruly, leaving teams to struggle to keep up with all the information being sent their way.
Searching for the Goldilocks Zone
Astronomers use the term Goldilocks Zone to refer to planets that revolve around their host stars at a distance where their surface temperature is temperate enough to support environments like our own. A cosmic happy medium. Likewise with monitoring, when gathering metrics and configuring dashboards and alarms, it’s important to create a happy medium that works for you and your team, so that you and can trust that you will be notified if and when a problem arises and that you will have the appropriate level of metrics to triage, troubleshoot, diagnose, and resolve it.
Soundcheck
In order to reign in a noisy monitoring system, or bypass the issue as much as possible if you happen to be creating a new one right now, you’ll need to set chunks of time aside to dig into your available resources – both resources and people. Once you know what you have available, you’ll need to start mapping out what you expect of each and make sure to refresh those expectations periodically, so that they change as your production requirements change.
Know Your Sources
If you haven’t already done so, it is important to take an initial “noise inventory” to document all the potential sources of alerts and metrics. This list can include, but is not limited to:
- Ticketing systems
- Chat + its integrations and plugins
- Infrastructure
- Knowledgebase / hosted wiki
- Source control
- Incident Manager
- Company product(s) – i.e. applications developed in-house for internal users, external users, or both.
- Other 3rd party applications and integrations
After you have your initial inventory, I recommend taking small amounts of time at regular intervals to keep the inventory up to date. This serves the added benefit of keeping you and your team familiar with your ecosystem as well as providing a central source for both onboarding new teammates and transparency to other teams.
Map Intentions, Paths, and Behaviors
Once the sources are documented, you can use these to start diagramming their actual and desired behaviors. Please don’t skip over the desired behaviors! This is important to ensure that the actual behavior is in alignment with what you expect. If you find that there are monitors configured differently than what you expect, now is the perfect time to change them! In general, when you are configuring an alarm the first question you should ask yourself is what your intentions are. More on the subject:
To drive home the importance of intention: you may find that there is a monitor configured to alert if the database instance is using less than X% of its memory. Upon investigation, you discover that the intention was to create an early warning in case of an issue with one or more of the microservices for your company’s application – the reasoning being that if the microservices generally use more than X% of memory, then less than that might indicate a problem.
Now that you know the intention, you can ask yourself, or your team, does the current configuration make sense? It might not – there are several reasons that one or more microservices might use fewer resources than expected. In this case, it probably makes sense to examine the microservices themselves and configure alerts based on their behaviors, e.g. alert when a service becomes unreachable, rather than all the potential causes. In fact, you may generally find monitors configured around causes are less effective than behaviors for this reason.
Configuring implementation is next. For every alert you have or plan to create you’ll need to ask yourself the following:
- What needs to be known
- Who needs to know it
- How soon do they need to know
- How do they need to be notified
Keeping with the earlier database example, let’s say that the database itself was suddenly unreachable. You’ll need to make sure that this alert reaches the engineers that are in charge of keeping track of your infrastructure. Depending on your configuration and if you’re using a 3rd party monitoring system, as opposed to any monitoring that is built into your cloud provider, you might diagram this out like so:
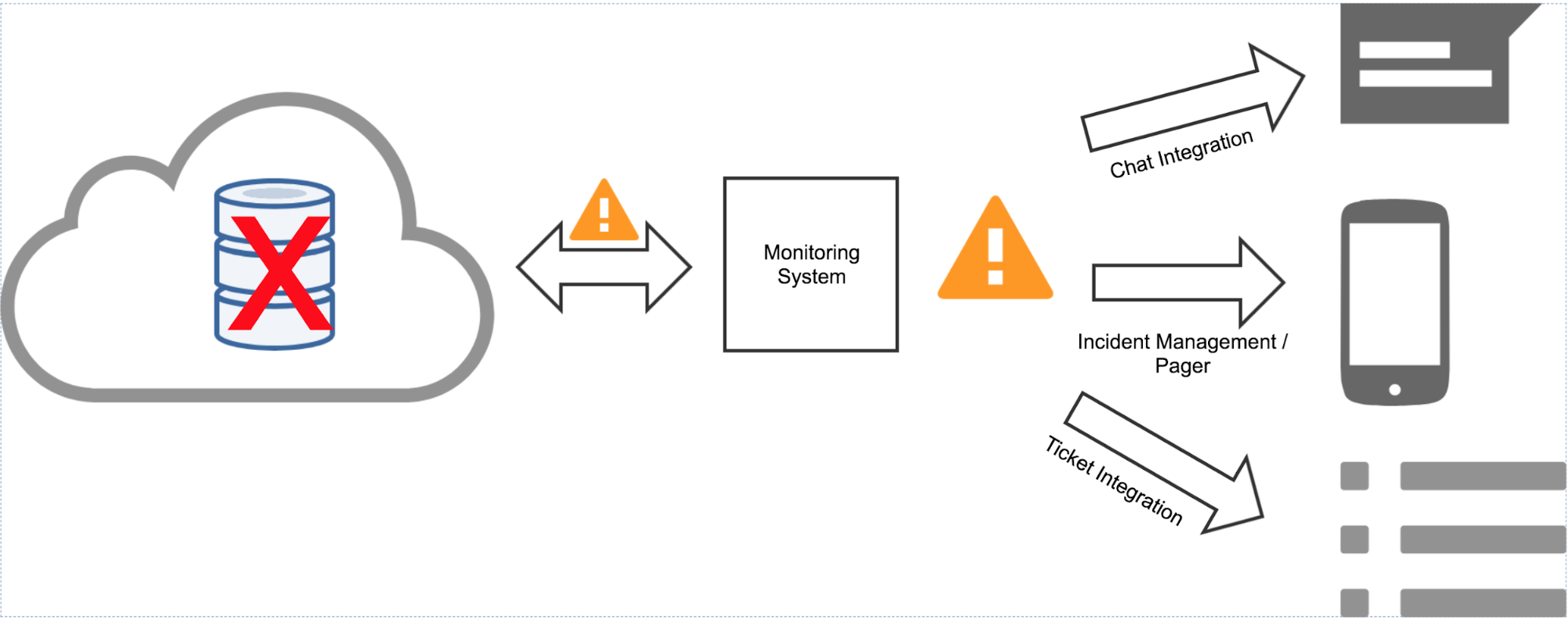
To drill down on this a little more, make sure that you are maximizing the capabilities of each tool at your disposal. For example, if you are using a certain tier of PagerDuty you can configure different behaviors for what behaviors you’ll see during your team’s normal business hours vs on-call / off-hours – for more information please take a look at their documentation.
Keep Your Monitors Lean and Clean
One of the best things that you can do to build trust with your monitors is to clean out the unnecessary ones. As part of the post-mortem for every incident, you should add the step of noting whether the alert was useful. Was someone paged at 2 am for an issue in a development environment rather than production? Was there an outage and no one was notified? Additionally, if no one was notified, is there an alert configured that was intended to notify for that type of incident? When assessing alerts, questions you should ask yourself will mainly center around:
- False positive: did an alert trigger when there was not an issue?
- False negative: did an alert fail to trigger when there was an issue?
- Frequency: is the same alert triggering repeatedly?
- Fixability: was the issue that caused the alert to trigger fixed? If so, was it a one-time fix or a permanent fix?
- Fragility: is the system being monitored fragile, in the sense that there are frequent outages and repairs needed?
Outright removing alerts can be an anxiety driven process, but in order to build and maintain a monitoring solution that you trust to notify you only when necessary and using the appropriate channels, frequent additions, updates, and even prunings are absolutely necessary.

You Might Also Like

SIEM vs. SOAR: What’s the Difference?

