
BigQuery vs. Athena: User Experience, Cost, and Performance
January 23, 2017

The trend of moving to serverless is going strong, and both Google BigQuery and AWS Athena are proof of that. Both platforms aim to solve many of the same challenges such as managing and querying large data repositories.
Announced in 2012, Google describes BigQuery as a “fully managed, petabyte-scale, low-cost analytics data warehouse.” You can load your data from Google Cloud Storage or Google Cloud Datastore or stream it from outside the cloud and use BigQuery to run a real-time analysis of your data.
In comparison, Amazon Athena, which was released only recently at the 2016 AWS re:Invent conference, is described as an “interactive querying service” that makes it easy to analyze data stored on Amazon S3 using standard SQL-run ad-hoc queries.
In this post, we will show you how you can use both tools and discuss the differences between them such as cost and performance.
User Experience
Executing Queries Using BigQuery
BigQuery can be used via its Web UI or SDK. In this section, we will briefly explain the terms used in the BigQuery service and discuss how you can quickly load data and execute queries.
Before you begin, you will need to go to the Google Cloud Platform to create the project.
After creating a new project (BigQuery API is enabled by default for new projects), you can go to the BigQuery page.
BigQuery allows querying tables that are native (in Google cloud) or external (outside) as well as logical views. Users can load data into BigQuery storage using batch loads or via stream and define the jobs to load, export, query, or copy data. The data formats that can be loaded into BigQuery are CSV, JSON, Avro, and Cloud Datastore backups.
In our demo, we used a simple public dataset and general data that can be used by anyone such as that of Major League Baseball (nice!).
We can click the Compose Query red button to enter the query we want to execute against the desired table. In our case, we looked to display 5,000 rows from the Wikipedia public dataset bigquery-public-data:samples.
We ran the query:
SELECT * FROM [bigquery-public-data:samples.wikipedia] LIMIT 5000;
and got the results in the table as shown below.
Note that BigQuery returned the results in 2.3 seconds, scanning over 35.7 GB of data. Different types of aggregations can be executed, for example, to sum the number of characters to return the lengths of articles.
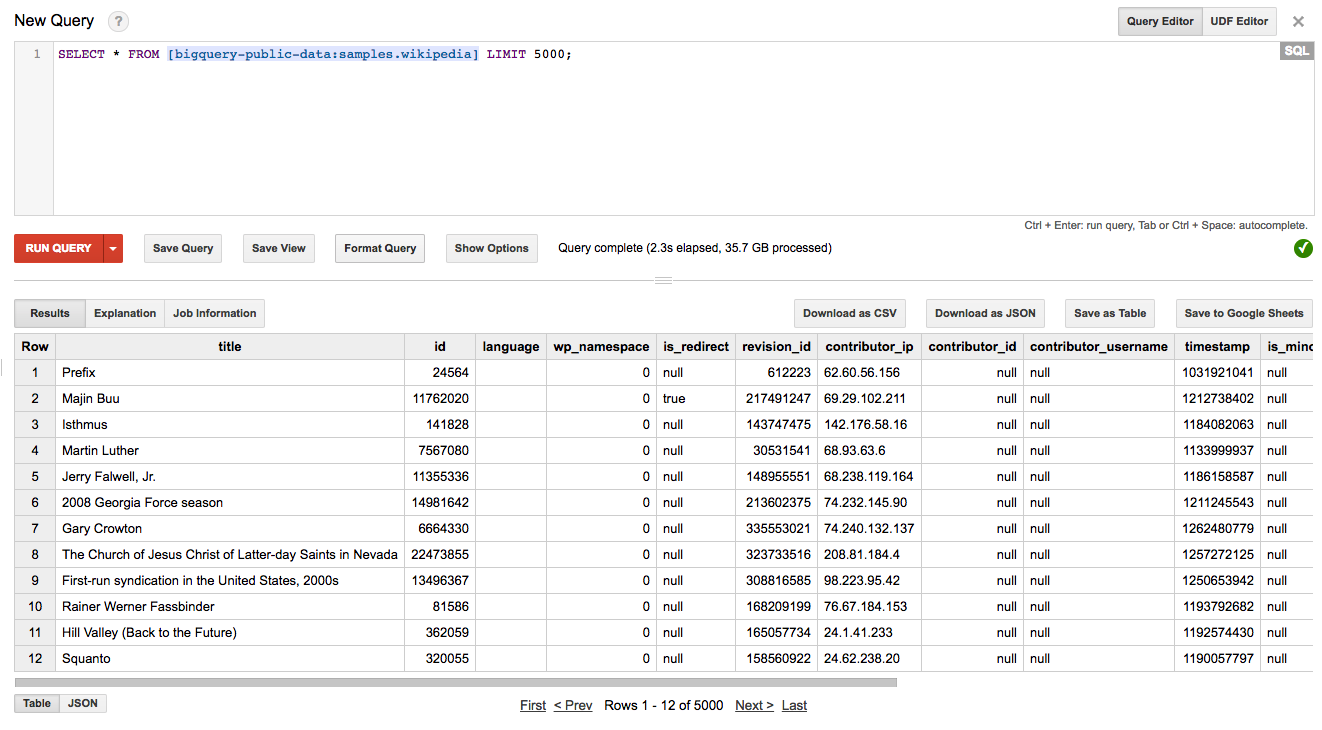
The List of 5,000 Rows, From the Wikipedia Dataset
The aggregation shown below was completed in 2 seconds, scanning over 2.34 GB of data.
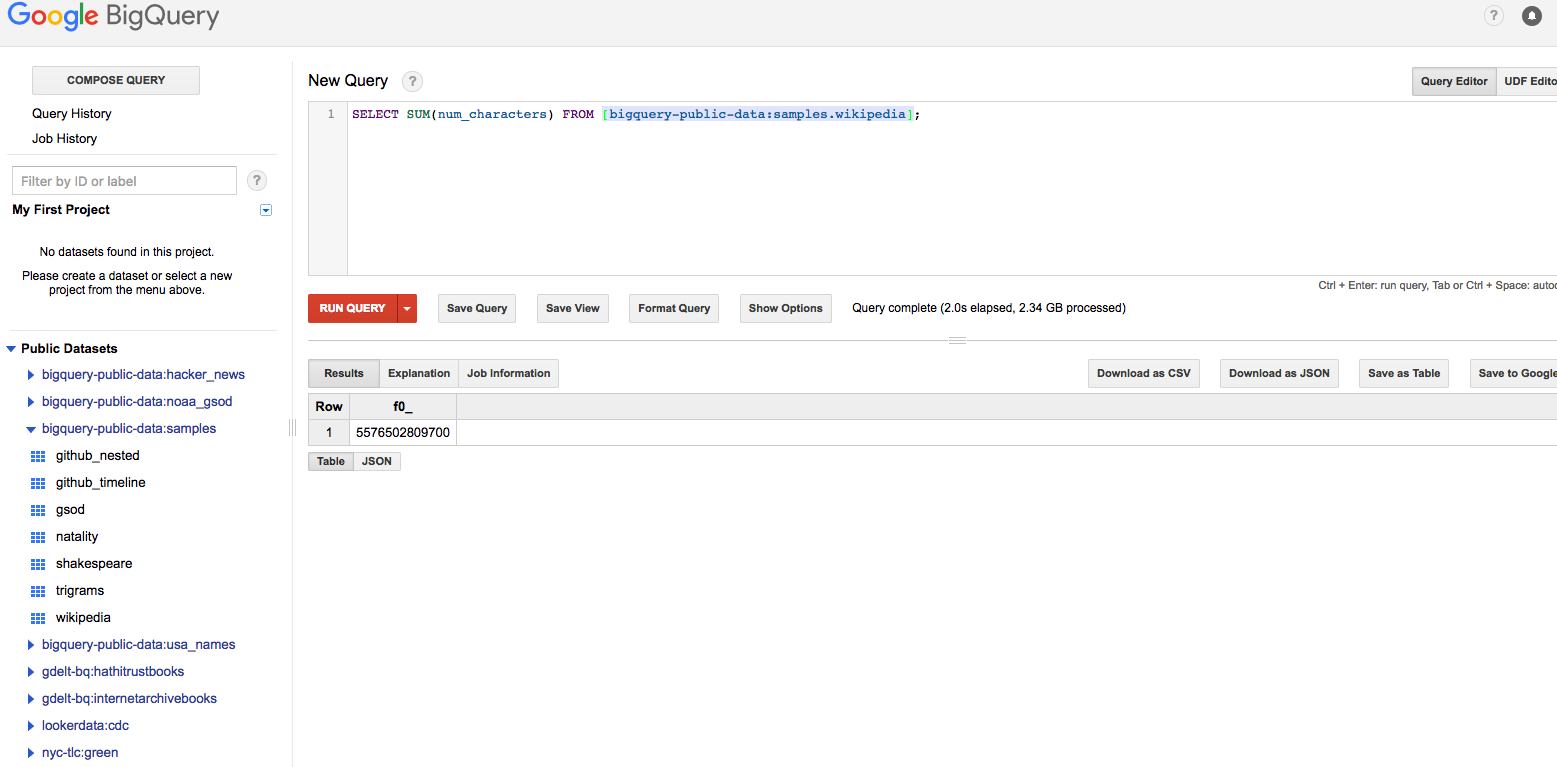
The Sum of the Number of Characters Column in the Wikipedia Table
In addition to the Web UI and command line, users can also connect to BigQuery using ODBC and JDBC drivers to enable it to be used locally with popular SQL tools such as SQL Workbench.
Executing Queries Using Amazon Athena
AWS Athena is based on the Hive metastore and Presto, where the Athena syntax is comprised of ANSI SQL for queries and relational operations such as select and join as well as Hive QL DLL statements for altering the metadata such as create or alter.
Like BigQuery, Athena supports access using JDBC drivers, where tools like SQL Workbench can be used to query Amazon S3. The data formats that can be loaded in S3 and used by Athena are CSV, TSV, Parquet Serde, ORC, JSON, Apache web server logs, and customer delimiters. Compressed formats like Snappy, Zlib, and GZIP can also be loaded.
Amazon Athena’s Web UI is similar to BigQuery when it comes to defining the dataset and tables. Through the Getting Started with Athena page, you can start using sample data and learn how the interactive querying tool works.
As shown below, you can access Athena using the AWS Management Console. In our case, we chose to query ELB logs:
Let’s try a few queries to see how quickly the results are returned. The queries and results are displayed below the Query Editor window.
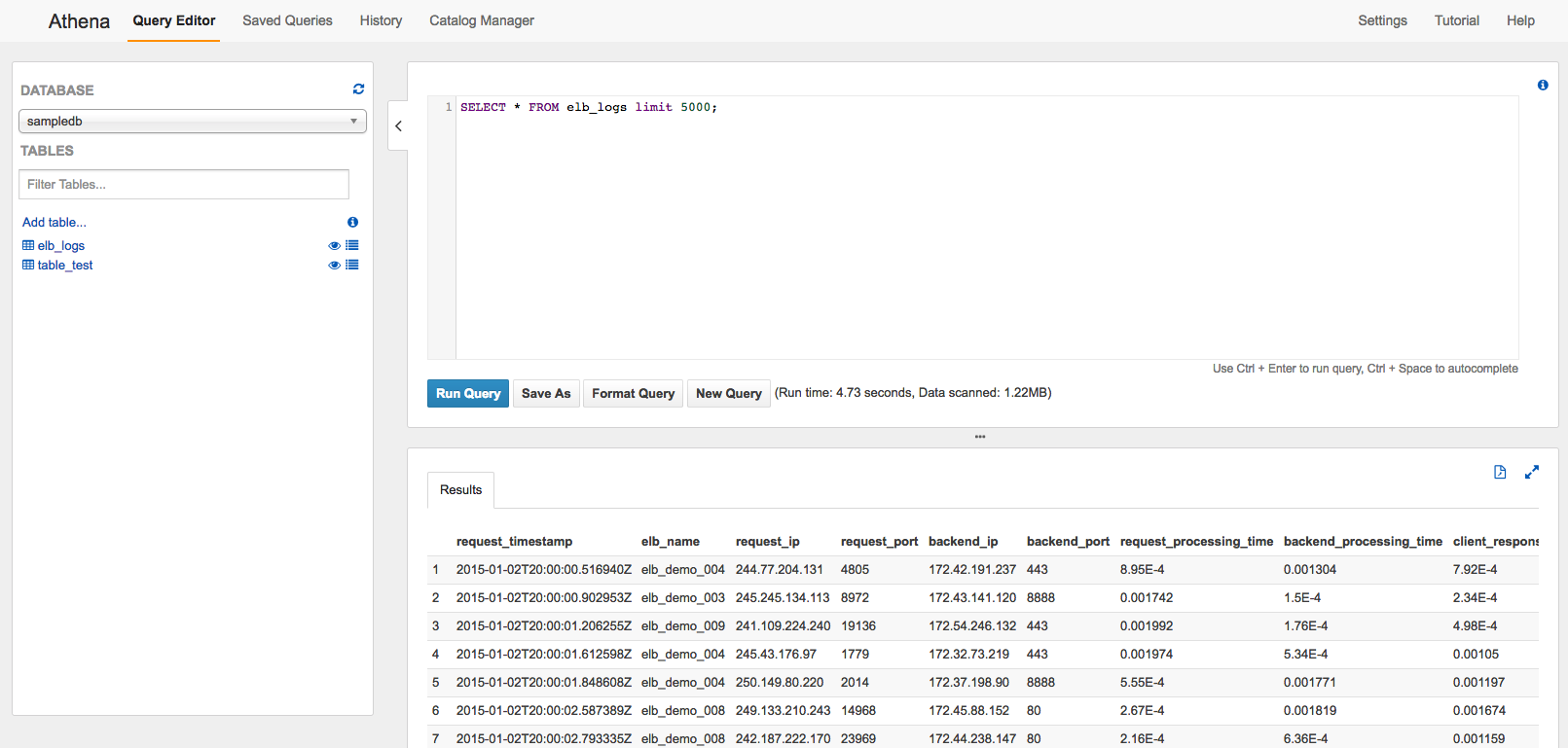
The Results from 5,000 Rows of the ELB Logs – 4.73 seconds
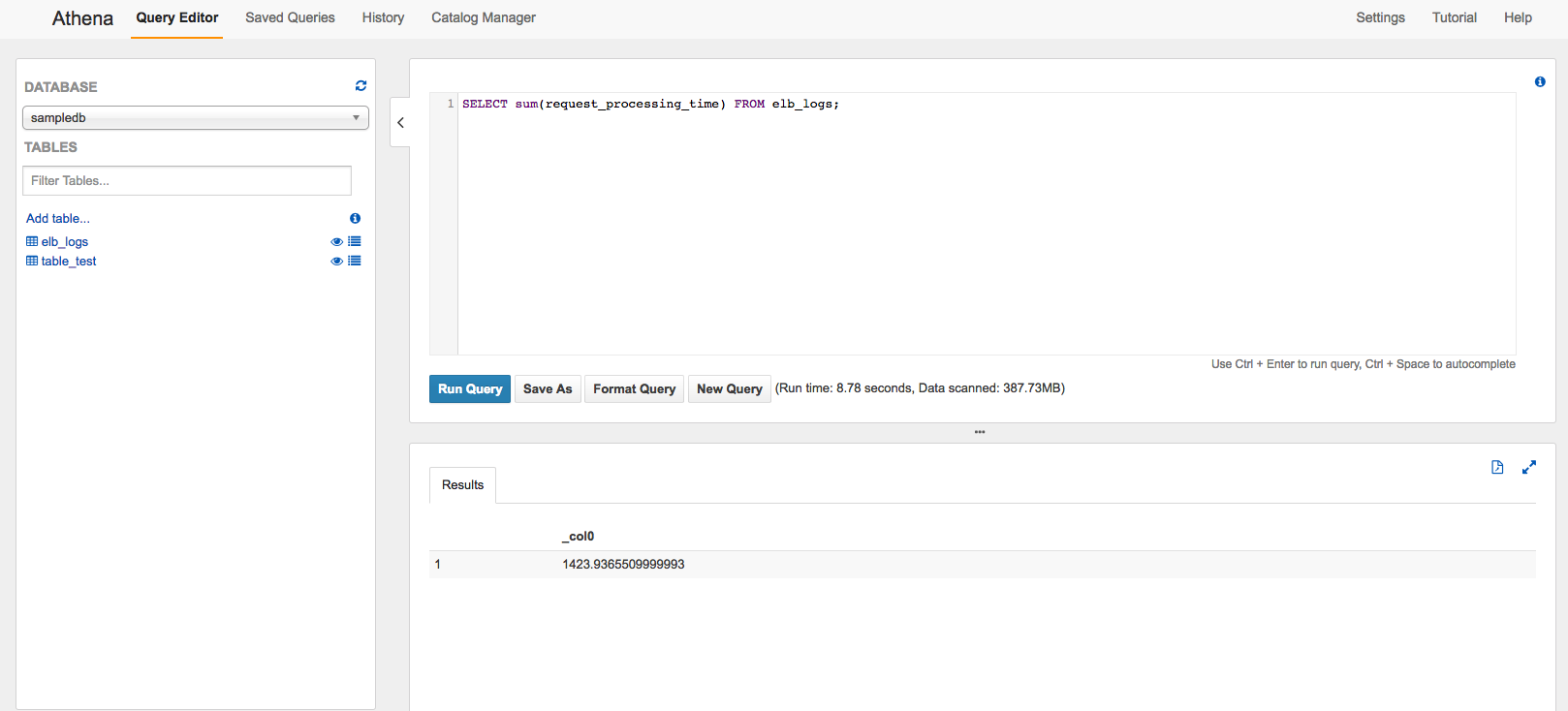
The Sum by Request Processing Time Column – 8.78 seconds
Athena vs. BigQuery
In the following sections, we will provide an in-depth comparison of these two tools.
Data Sources
As mentioned above, BigQuery supports native tables. These are optimized for reading data because they are backed by BigQuery storage, which automatically structures, compresses, encrypts, and protects the data. In addition, BigQuery can also run on external storage. In comparison, Athena only supports Amazon S3, which means that a query can be executed only on files stored in an S3 bucket.
Price
The price models for both solutions are the same. Users pay for the S3 storage and the queries that are executed using Athena. AWS Athena is paid per query, where $5 is invoiced for every TB of data that is scanned. Check Amazon’s Athena pricing page to learn more and see several examples.
Google also charges by the amount of data scanned, and the price is the same as for Athena. The storage is $0.02 per GB, which is more or less the same in AWS (the price tiers depends on the overall amount stored). All other operations such as loading data, export, copy or metadata are free.
Performance
When it comes to speed, the native tables in BigQuery show good performance. Below, we examined another public dataset called bigquery-public-data.github_repos.licenses. We loaded the same data set to an S3 bucket and executed the following SQL statement, counting the number of licenses in the table (grouped by the license number):
SELECT license, COUNT(*) AS licenses FROM [bigquery-public-data.github_repos.licenses] GROUP BY license ORDER BY licenses DESC
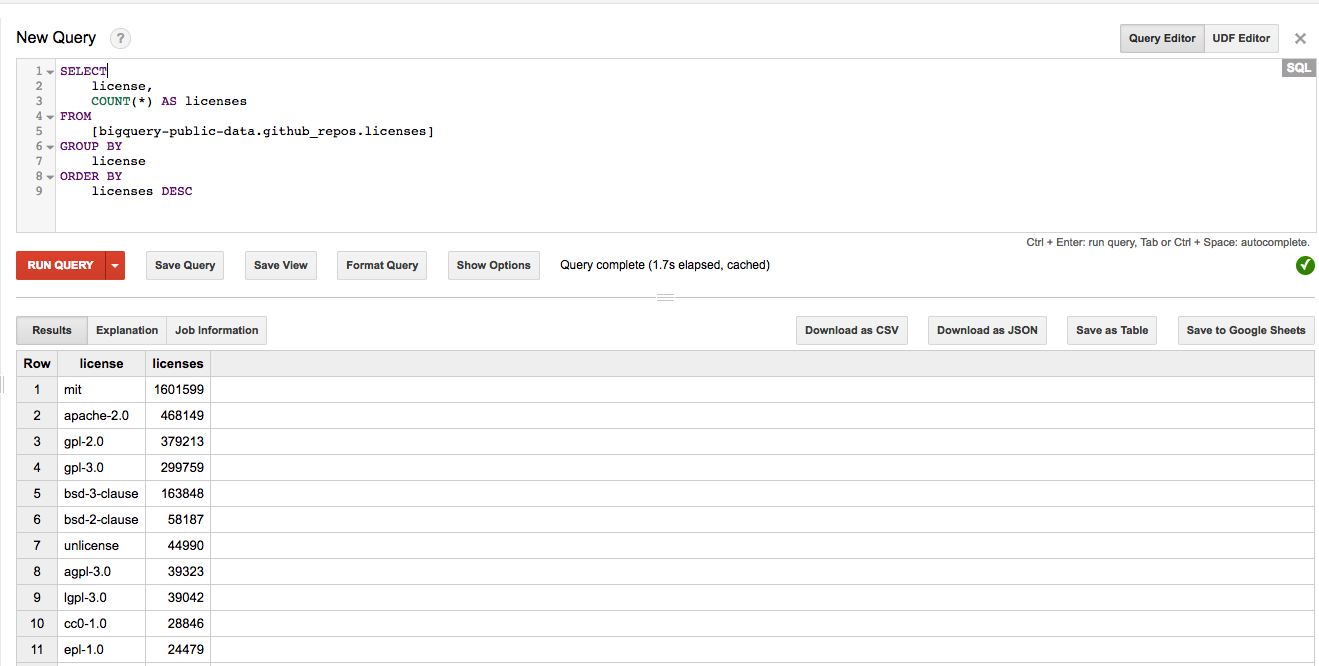
BigQuery Result for Counting the Licenses – 1.7 seconds
We checked the same results in Athena. The results are shown below:
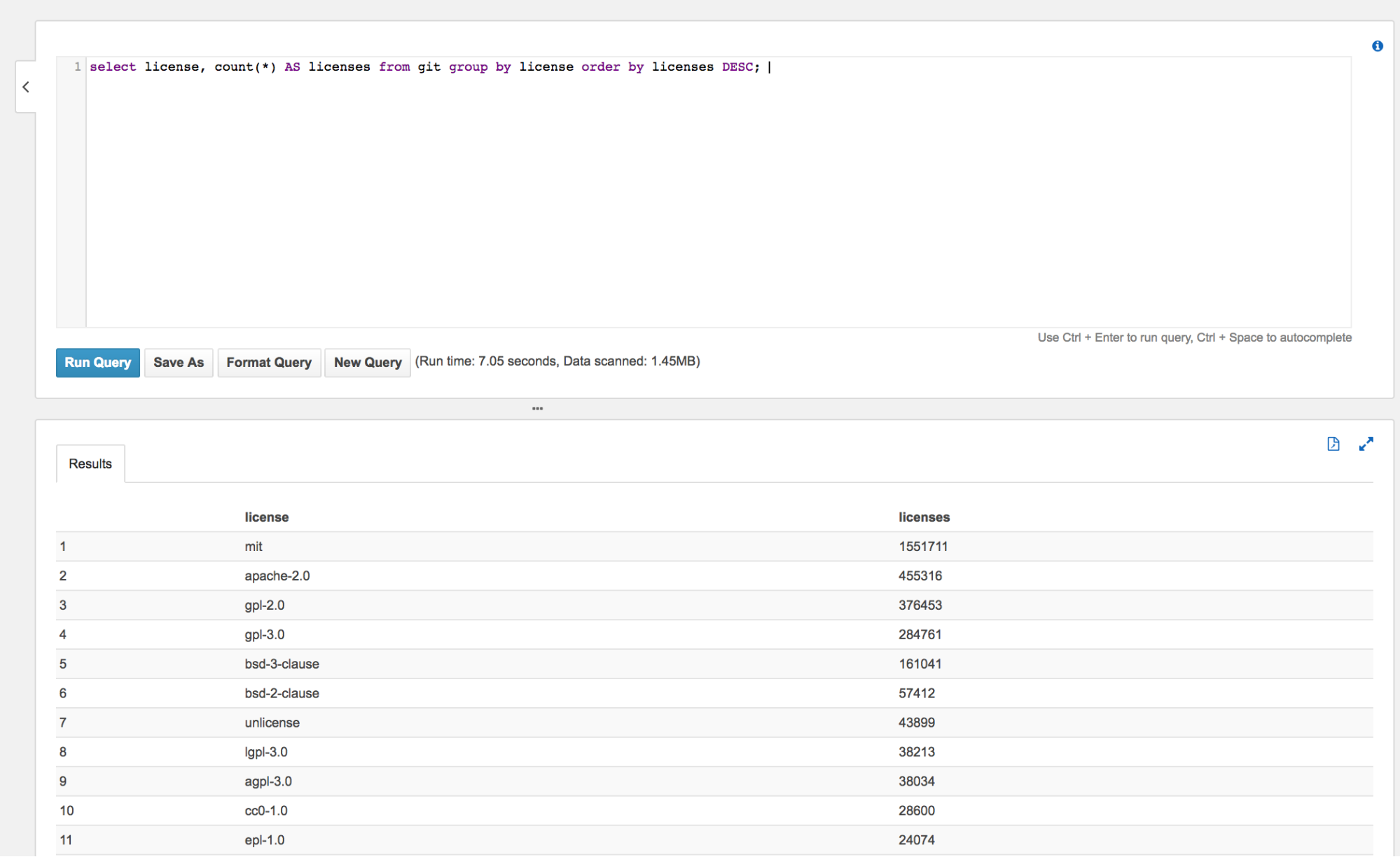
Athena Result for Counting Licenses – 7.05 seconds
We see that using BigQuery shows better performance than AWS Athena, but obviously that will not always be the case.
It’s important to note that Amazon Athena supports data partition by any key (unlike BigQuery, which supports date only). With Athena, you can also restrict the amount of scanned data by each query — which leads to improved performance and reduced costs.
UDF Support
The next way in which BigQuery and Athena differ is in the User Defined Functions (UDF). In BigQuery, this is a JavaScript function that can be called as part of a query, an action that provides powerful functionality where mixing SQL and the code is possible. One example of this is implementing custom converters that don’t exist, such as the URL decode function.
For data engineers, UDF is a powerful tool that Athena currently does not support, and the only way to add it is to contact their team at athena-feedback (at) amazon.com. But as we know from Amazon’s release cadence, UDF will be introduced soon.
Summary
So, what can we expect from Athena and BigQuery going forward? At this stage, Athena offers a high-level service for querying data already stored in S3. If you’re already an AWS services user and you have data to analyze, just create a table point on S3 and you’re ready to query. What would be nice to have from Athena is additional operations in a table such as appending results of a query to an existing table.
More on the subject:
Overall, Athena as a new product has potential, and it’s worth waiting to see what it will offer in the near future. As far as BigQuery, although some features are missing such as partitioning with any column in a table, the solution is mature and feature-rich and offers users a good and robust data warehouse solution.

You Might Also Like

AI in Observability: Mapping Root Causes with Precision

