Create a Security Rule
Security rules help you connect the dots between your data sources and events that could indicate a security threat or breach. Your Cloud SIEM account comes preconfigured with security rules for different attack types and security use cases.
You can create new security rules to supplement the built-in rules. You can also update any preconfigured rule at any time, including adding a notification endpoint (for example, email or Slack) or changing trigger thresholds.
You cannot configure rules using the logzio-alert log type. This type is ignored by the rule engine.
Manually create a new rule
You can create your own custom rules. To get started, navigate to SIEM > Rules and select New rule.

Name the rule
Give your rule a meaningful name. When your rule triggers, its name is used as the email subject or notification heading.
Your rule name can contain letters, numbers, spaces, and special characters. It can't contain emojis or any other elements.
Set search components
Next, set the search components. This determines which logs to look for and in which accounts.
You can use any combination of filters and a search query. Note the following:
- Use a Lucene search query.
- You have the option to use wildcards.
- OpenSearch Dashboards Query Language (DQL) is not supported.
- All filters are accepted, including: is, is not, is one of, is not one of, exists, does not exist.
After refining your search query and filters, click Preview to open OpenSearch Dashboards in another tab and review the returned logs to ensure you get the expected results.
To perform date range filtering on the @timestamp field, include the field as part of a query rather than adding it as a filter: @timestamp filters are overwritten.

Use group-by (order matters!)
:::crucial Important Alerts won't trigger if the field added to the Group-by doesn't exist in the logs. The logs must include both the field you have in group-by and the field you use in your query/filter to trigger the alert. :::
You can apply group by operators to up to 3 fields. If you use this option, the rule will return the aggregated results.
The order of group-by fields matters. Results are grouped in the order in which the group-by fields are added. (The fields are shown from first to last from left-to-right.)
For example, the following will group results by continent, then country, then city:

If you reverse the order (city, country, continent), it will likely generate unintended results.
Select relevant accounts
Next, select the Accounts to search.
If you select All accounts, the rule will query the logs in all the accounts to which it has access. It will automatically include any accounts added in the future.
You can select specific accounts. Select Just these accounts and add the relevant accounts from the dropdown list.
Set threshold and severity levels
Set your threshold and severity levels. You can base your trigger on a number of logs, minimum/maximum of fields, average, sum, and more.
In the Trigger if... section, click Add a threshold to set as many as 5 threshold conditions, each with its own severity tag.
You can set the trigger condition time frame between 5 minutes and up to 24 hours (1 day). To set a trigger condition longer than 24 hours, use Logz.io’s API to create your rule.

(Optional) Add MITRE ATT&CK Tags
MITRE ATT&CK is a curated knowledge base and model for cyber adversary behavior, reflecting the various phases of an adversary’s attack lifecycle and the platforms they are known to target.
You can add the predefined MITRE tags to your security rules and get an alert when a known cyber security threat is found in your systems.

Click on Add tags and choose the Tactics (Why) and Technique (How) you’d like to monitor. For some Techniques, you’ll be able to select a Sub-technique to get more in-depth monitoring of it.
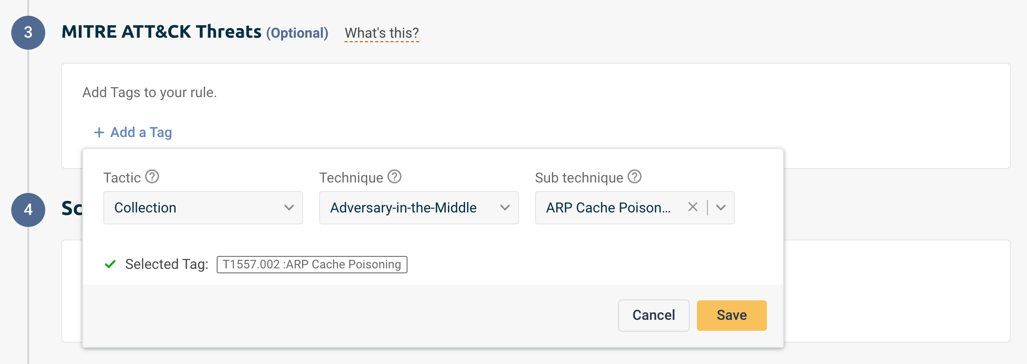
Click on your saved tags to view MITRE’s documentation and additional information for each one.
Set rule schedule
You can use the scheduling mechanism to manage the trigger condition frequency.
Scheduling defines the frequency and the time frame for the rule. To define a schedule, select On Schedule and use a cron expression to specify when to trigger the rule.
The cron expression can only be set in increments rounded to the nearest minute.
For example, you can apply the following schedule to your rules:
| Cron expression | Rule trigger schedule |
|---|---|
| 0 0/10 ? * * | Every 10 minutes |
| 0 0 0/1 ? * * * | Rounded to the nearest hour |
| 0 8-17 ? MON,TUE,WED,THU,FRI * | Every minute between 8 am to 5 pm, Monday through Friday |
| 0 5 0 ? * * * | Every day at exactly 12:05 am |
By default, trigger conditions run approximately every minute. If there's a lag, the rule is checked once all data is received. In addition, once a rule has met its condition and is triggered, it won't be checked again for the remainder of the rule trigger condition time range.

(Optional) Set notification details
The rule's Description is visible on the rule definitions page, and it's part of the emails and Slack messages sent when the rule is triggered. As such, an ideal description will be helpful to recipients, explaining how to fix the issues that led to the rule.
The Tags are helpful for filtering and finding the rules later on. You can add up to 25 tags per rule.
You can choose a notification endpoint to send notifications or emails when the rule is triggered. This isn't required, though—triggered rules are still logged and searchable in OpenSearch Dashboards.
Choose the endpoints or email addresses you want to notify when the rule triggers.
Add email address as a recipient
Notification emails include up to 10 sample events. If your rule triggers more than 10 events, you can view the complete list in your logs.
To use an email as your endpoint, type the email in the Recipients box and click enter.
Set a period between notifications to limit how frequently recipients are notified. Logz.io will continue to log triggered rules without sending notifications, and you can review these directly from the Logz.io platform at any time.
The system combines the Trigger if time interval with the Wait time interval to calculate how long it should snooze notifications and chooses the more extended time duration available. For example, if your trigger condition is 1 hour and the wait time is 15 Minutes, the system will snooze notifications for 1 hour before triggering them again.
If you need help adding a new endpoint, see Notification endpoints.
Select rule output format & content
When triggered, the rule will send out a notification with sample data.
Sample data can be sent in either JSON or Table formats. Toggle the button to select your preferred format.
If the rule includes any aggregation or group by rule, the notification output defaults to the group by/aggregated fields.
Otherwise, you control the data format. It can be either JSON or a Table.
- If you select JSON, you can choose to send all fields or select fields.
- If you select a table, you can send as many as 7 fields.
To be selective about the output, click Add a field and select a field from the dropdown list. If you want, you can also add a sorting rule and a regex filter.

When notifications are suppressed, Logz.io will continue to log triggered rules without sending notifications. You can search triggered rule logs at any time.
Using regex filters
You can "clean" the data in the notification using regex filters. If you add a regex filter, it will select for the data you want to include in the rule output.
There is no danger that a regex filter will disrupt the notification.
- If the regex matches the relevant data, you will see only the desired results.
- If the regex does not match, the filter will be disregarded and the rule output will include the full content of the field.
Save your rule
Click Save to save your rule. Whenever the thresholds are met, the rule will trigger. Logz.io will log the security event, and send out a notification, if configured.
Duplicate and modify an existing rule
You can create rules based on Logz.io's preconfigured rules. In this case, the builder will be pre-populated with data from the existing rule, such as the query string.
Navigate to SIEM > Rules and choose the rule you want to use. Hover over the three dots and select Duplicate.

The rule configuration wizard includes all of the preconfigured queries, filters, etc.
Now, you can edit the rule based on your needs and set the trigger conditions, schedule, notification endpoints, etc.
Once you're done, click Save to create the rule.
Create a rule from OpenSearch Dashboards query
You can create rules based on queries and filters in OpenSearch Dashboards.
Navigate to SIEM > Research and build your query.
To turn the query into a rule, click on Create from query > Create rule. The rule will include the query and filters you've used.

Next:
- Name your rule
- Set the trigger conditions
- Add MITRE ATT&Ck tags if needed
- Set schedule
- Choose the notification points.
Once you're done, click Save to create the new rule.