AWS S3 Access
Amazon S3 Access Logs provide detailed records about requests that are made to your S3 bucket. This integration allows you to send these logs to your Logz.io account.
Configuration
Before you begin, you'll need:
s3:ListBucketands3:GetObjectpermissions for the required S3 bucketFile names in ascending alphanumeric order. This is important because the S3 fetcher's offset is determined by the name of the last file fetched. We recommend using standard AWS naming conventions to determine the file name ordering and to avoid log duplication.
Send your logs to an S3 bucket
Logz.io fetches your S3 access logs from a separate S3 bucket. By default, S3 access logs are not enabled, so you'll need to set this up.
For help with this, see Amazon S3 Server Access Logging from AWS.
Add a new S3 bucket using the dedicated Logz.io configuration wizard
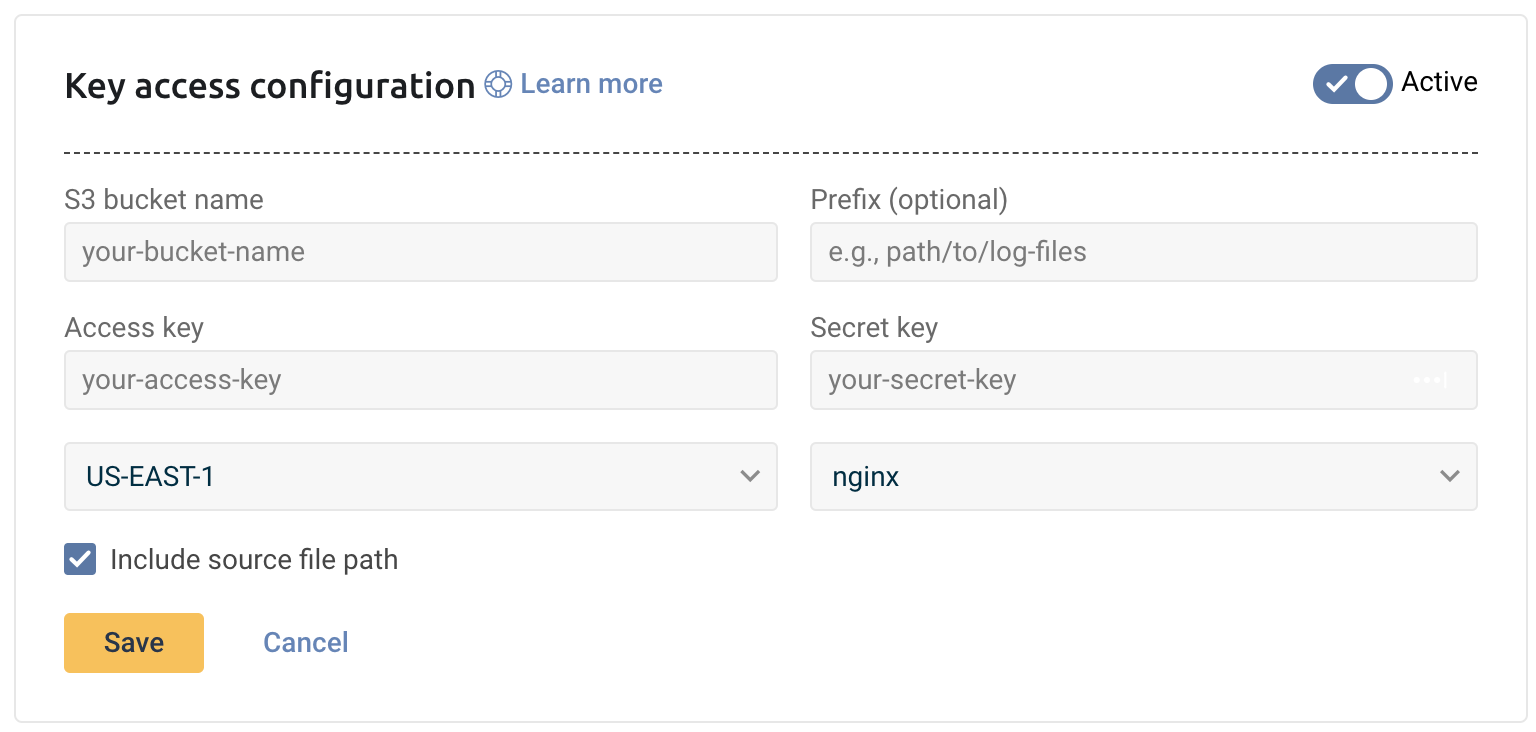
Log into the app to use the dedicated Logz.io configuration wizard and add a new S3 bucket.
- Click + Add a bucket
- Select your preferred method of authentication - an IAM role or access keys.
The configuration wizard will open.
- Select the hosting region from the dropdown list.
- Provide the S3 bucket name
- Optional You have the option to add a prefix.
- Choose whether you want to include the source file path. This saves the path of the file as a field in your log.
- Save your information.

Logz.io fetches logs that are generated after configuring an S3 bucket. Logz.io cannot fetch old logs retroactively.
Check Logz.io for your logs
Give your logs some time to get from your system to ours, and then open Open Search Dashboards.
If you still don't see your logs, see log shipping troubleshooting.